Olá, Marcel!
Não se preocupe que pode confundir um pouco mesmo.
Existem formas diferentes de fazer a mesma operação. O uso do reset_index() ajuda a escolher os nossos valores usando o .loc() atrelado ao valor da varíavel elemento_md, pois o index varia de 0 até 5 no nosso exemplo.
Sendo assim, poderíamos utilizar notas_beltrano.loc[elemento_md - 1] quando utilizamos o reset_index(), pois ele pesquisaria no nosso dataframe notas_beltrano a linha cujo index é igual a 2.
No entanto, o que isso retorna?
Isso retorna a linha inteira dos nosso dados, ou seja, se eu quiser apenas pegar o valor das notas para calcular a mediana, eu seria obrigado a especificar que coluna tem essa nota.
Vou deixar a abaixo três formas possíveis e que segue a ideia do que estamos aprendendo nas aulas de como resolver esse problema.
1. Usando o reset_index() sem .loc() e especificando a coluna das notas
# Dividindo o código em pequenos blocos, caso queria testar isoladamente cada bloco na sequência
notas_beltrano = df.Beltrano.sample(6, random_state = 101)
notas_beltrano
notas_beltrano = notas_beltrano.sort_values()
notas_beltrano
# Usando o reset_index
notas_beltrano = notas_beltrano.reset_index()
notas_beltrano
n = notas_beltrano.shape[0]
n
elemento_md = int (n / 2) - 1
elemento_md
# Não precisa usar .loc(), mas é necessário especificar a coluna onde estão as notas para o cálculo da mediana. O "Beltrano" indica a coluna de notas e o elemento_md a posição da nota no DataFrame.
elemento_md1 = notas_beltrano.Beltrano[elemento_md]
elemento_md2 = notas_beltrano.Beltrano[elemento_md + 1]
mediana = (elemento_md1+ elemento_md2) / 2
mediana
2. Usando o reset_index() com .loc() e especificando a coluna das notas
Note que nesse exemplo, ao utilizar o .loc() adquirimos toda a informação da linha desenhada e não apenas a nota e, portanto, precisamos isolá-la através do comando elemento_md1["Beltrano"] e elemento_md2["Beltrano"], ou se quiser compilar o raciocínio notas_beltrano.loc[elemento_md]["Beltrano"] e notas_beltrano.loc[elemento_md + 1]["Beltrano"].
# Dividindo o código em pequenos blocos, caso queria testar isoladamente cada bloco na sequência
notas_beltrano = df.Beltrano.sample(6, random_state = 101)
notas_beltrano
notas_beltrano = notas_beltrano.sort_values()
notas_beltrano
# Usando o reset_index
notas_beltrano = notas_beltrano.reset_index()
notas_beltrano
n = notas_beltrano.shape[0]
n
elemento_md = int (n / 2) - 1
elemento_md
# Usando o .loc(), isolamos em elemento_md1 e elemento_md2 os dados que nos importam para o cálculo da mediana. Mas para conseguir calculá-la, precisamos extrair apenas os valores das notas.
elemento_md1 = notas_beltrano.loc[elemento_md]
elemento_md2 = notas_beltrano.loc[elemento_md + 1]
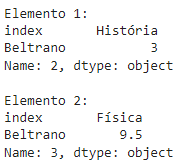
# Print exibindo o comportamento supracitado (no tópico tem o print do código)
print(f"Elemento 1:\n{elemento_md1}\n\nElemento 2:\n{elemento_md2}")
# Extraindo apenas os valores das notas
mediana = (elemento_md1["Beltrano"] + elemento_md2["Beltrano"]) / 2
mediana
Trecho do código gerado no print:
3. Usando apenas o .iloc()
Esse exemplo é ideêntido ao do tópico anterior do fórum, mas com o ajuste do nome de uma das variáveis para facilitar a interpretação e notar as diferenças entre os códigos.
# Dividindo o código em pequenos blocos, caso queria testar isoladamente cada bloco na sequência
notas_beltrano = df.Beltrano.sample(6, random_state = 101)
notas_beltrano
notas_beltrano = notas_beltrano.sort_values()
notas_beltrano
n = notas_beltrano.shape[0]
n
elemento_md = int (n / 2) - 1
elemento_md
elemento_md1 = notas_beltrano.iloc[elemento_md]
elemento_md2 = notas_beltrano.iloc[elemento_md + 1]
mediana = (elemento_md1 + elemento_md2) / 2
mediana
Qual método é o melhor a se utilizar?
Depende do gosto do freguês (hehehehe). Entretanto, como vimos na aula, existe apenas uma linha de código que ajudaria a fazer o cálculo sem dores de cabeça que seria notas_beltrano.median().
Espero ter ajudado e qualquer dúvida é só chamar!
Bons estudos!


