Oii Pedro, como você está?
Peço perdão pela demora em obter um retorno.
Se todas as URL seguirem a mesma estrutura de JSON como em seu exemplo, podemos utilizar o código abaixo para o seu objetivo:
lista_dataframes = []
for indice, linha in df_url.iterrows():
tabela_completa = pd.read_json(df_url['URL da API'][indice])
tabela_normalizada = pd.json_normalize(tabela_completa['historicoTaxas'])
tabela_normalizada['emissorCnpj'] = tabela_completa['emissorCnpj']
tabela_normalizada['emissorNome'] = tabela_completa['emissorNome']
lista_dataframes.append(tabela_normalizada)
todas_as_informacoes = pd.concat(lista_dataframes)
Foi necessário a utilização da função json_normalize em uma coluna específica: a historicoTaxas, uma vez que essa coluna é referente a uma lista de informações que existe no JSON original, ou seja, há uma estrutura aninhada onde temos uma lista e dentro dessa lista possuímos outros objetos de chave e valor. E caso não utilizássemos a abordagem do json_normalize, teríamos como resultado uma coluna que possuiria um dicionário como valor, como mostro abaixo:
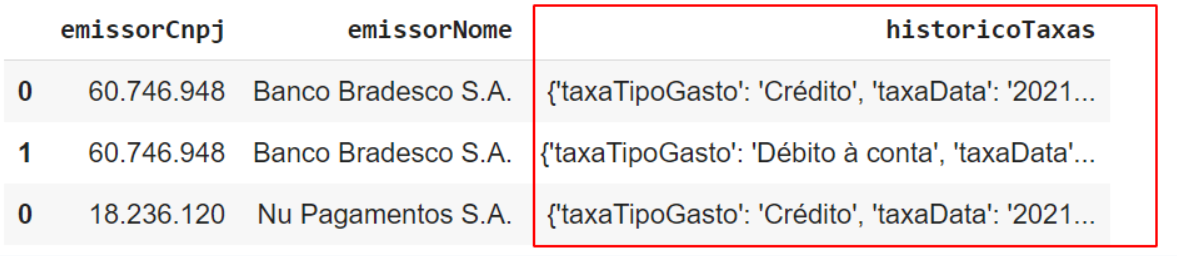
Mas, utilizando da primeira abordagem, teremos como resultado o seguinte:
 Por fim, caso seja necessário filtrar por banco, uma das maneiras de chegarmos a isso é utilizarmos a função contains e passarmos o nome do banco que estamos procurando, veja:
Por fim, caso seja necessário filtrar por banco, uma das maneiras de chegarmos a isso é utilizarmos a função contains e passarmos o nome do banco que estamos procurando, veja:
todas_as_informacoes[todas_as_informacoes['emissorNome'].str.contains('Banco Bradesco S.A.')]
Resultado:

Deixo como referência para consultas futuras, a documentação da função json_normalize.
Qualquer dúvida fico à disposição.
Grande abraço!


