E aí João! Tudo certinho?
Sinto muito pela demora em lhe dar um retorno.
Esse erro está informando que não existe índice em variáveis que são escalares (variáveis que possuem apenas um número). Portanto, provavelmente o que pode ter acontecido é de, no decorrer do seu código, você ter atribuído algum valor escalar para a variável limite_superior
Vamos fazer o seguinte, primeiro tenta rodar todo o seu código novamente. Desde o início quando você importa seus dados e armazena na variável dados. Você pode fazer isso de maneira mais rápida clicando na opção Kernel > Restart and Run All:
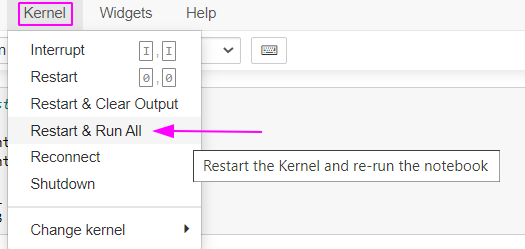
Após feito isso, verifique se o erro ainda persiste.
Caso sim, confere pra gente se a sua variável limite_superior está armazenando uma Series, conforme a mostrada na imagem abaixo:
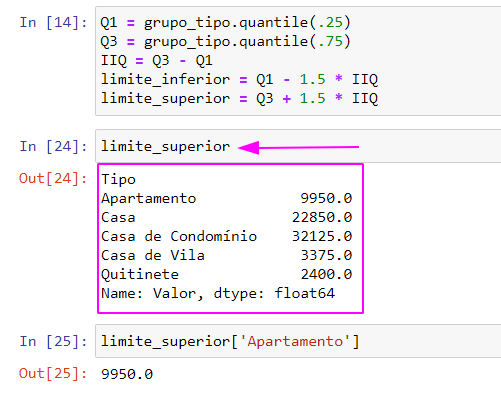
Se ela não estiver armazenando essa Series, você deve verificar se a sua variável dados está armazenando o conteúdo do arquivo dados_residencial.csv. Para garantir que ela esteja armazenando os dados corretos, você pode fazer assim:
# importando os dados
dados = pd.read_csv('dados/aluguel_residencial.csv', sep = ';')
grupo_tipo = dados.groupby('Tipo')['Valor']
Q1 = grupo_tipo.quantile(.25)
Q3 = grupo_tipo.quantile(.75)
IIQ = Q3 - Q1
limite_inferior = Q1 - 1.5 * IIQ
limite_superior = Q3 + 1.5 * IIQ
Espero que isso te ajude. Se ficar com alguma dúvida me avisa, vou estar por aqui :)
Bons estudos!


