
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
x = data[['horas_esperadas', 'preco']]
y = data['finalizado']
SEED = 8
np.random.seed(SEED)
raw_train_x, raw_test_x, train_y, test_y = train_test_split(x, y, test_size=0.25, stratify=y)
print("We train with %d elements and test with %d elements" % (len(train_x), len(test_x)))
model = SVC(gamma='auto')
model.fit(raw_train_x, train_y)
predictions = model.predict(raw_test_x)
accuracy = accuracy_score(test_y, predictions) * 100
print("The accuracy is %.2f%%" % accuracy)
basePredictions = np.ones(540)
accuracy = accuracy_score(test_y, basePredictions) * 100
print("The accuracy is %.2f%%" % accuracy)
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(raw_train_x)
train_x = scaler.transform(raw_train_x)
test_x = scaler.transform(raw_test_x)
data_x = test_x[:,0]
data_y = test_x[:,1]
x_min = data_x.min()
x_max = data_x.max()
y_min = data_y.min()
y_max = data_y.max()
pixels = 100
x_axis = np.arange(x_min, x_max, (x_max - x_min)/pixels)
y_axis = np.arange(y_min, y_max, (y_max - y_min)/pixels)
xx, yy = np.meshgrid(x_axis, y_axis)
coordinates = np.c_[xx.ravel(), yy.ravel()]
z = model.predict(coordinates)
z = z.reshape(xx.shape)
plt.contourf(xx, yy, z, alpha=0.3)
plt.scatter(data_x, data_y, c=test_y, s=4)
plt.show()Resultado:
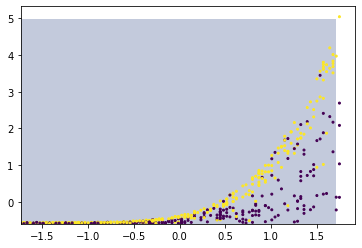
A curva de classificação não é exibida.

