Olá Pessoal, poderiam dar um direcionamento de como posso replicar no Pandas a formula "SE" que utilizo no excel para criar colunas calculadas? Estou tentando replicar tudo no Pandas.
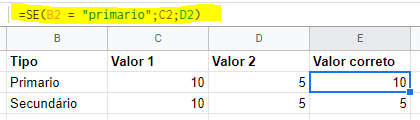
Abaixo um exemplo fictício para ilustração:
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Olá Pessoal, poderiam dar um direcionamento de como posso replicar no Pandas a formula "SE" que utilizo no excel para criar colunas calculadas? Estou tentando replicar tudo no Pandas.
Abaixo um exemplo fictício para ilustração:


Olá, Tacio! Tudo bom?
Você pode utilizar uma função anônima no Python, também chamada de função lambda que vai criar a nova coluna df['Valor correto'] com base nos valores anteriores, e para aplica-lá ao pd.DataFrame, você utiliza o método pd.DataFrame.apply(). O exemplo é ilustrado abaixo:
import pandas as pd
dados = {'Tipo': ['Primario', 'Secundario'],
'Valor 1': [10, 10],
'Valor 2': [5, 5]
}
df = pd.DataFrame(dados)
dfA saída é:
| Tipo | Valor 1 | Valor 2 | |
|---|---|---|---|
| 0 | Primario | 10 | 5 |
| 1 | Secundario | 10 | 5 |
E para criar a nova coluna, podemos usar
df['Valor correto'] = df.apply(lambda x: x['Valor 1'] if x['Tipo'] == 'Primario' else x['Valor 2'], axis = 1)Onde o resultado é:
| Tipo | Valor 1 | Valor 2 | Valor correto | |
|---|---|---|---|---|
| 0 | Primario | 10 | 5 | 10 |
| 1 | Secundario | 10 | 5 | 5 |
A função lambda avalia cada linha do DataFrame, por isso o parâmetro axis = 1, e com base nas colunas de cada linha, decide entre Valor1 e Valor2 para a coluna Valor correto.
Se ainda tiver alguma dúvida, estou por aqui. Ótimos estudos e grande abraço!