
Alguém pode me ajudar estou tentando criar gráficos de series mas a formatação funciona quando rodo no spyder, mas no power bi fica totalmente diferente os gráficos.
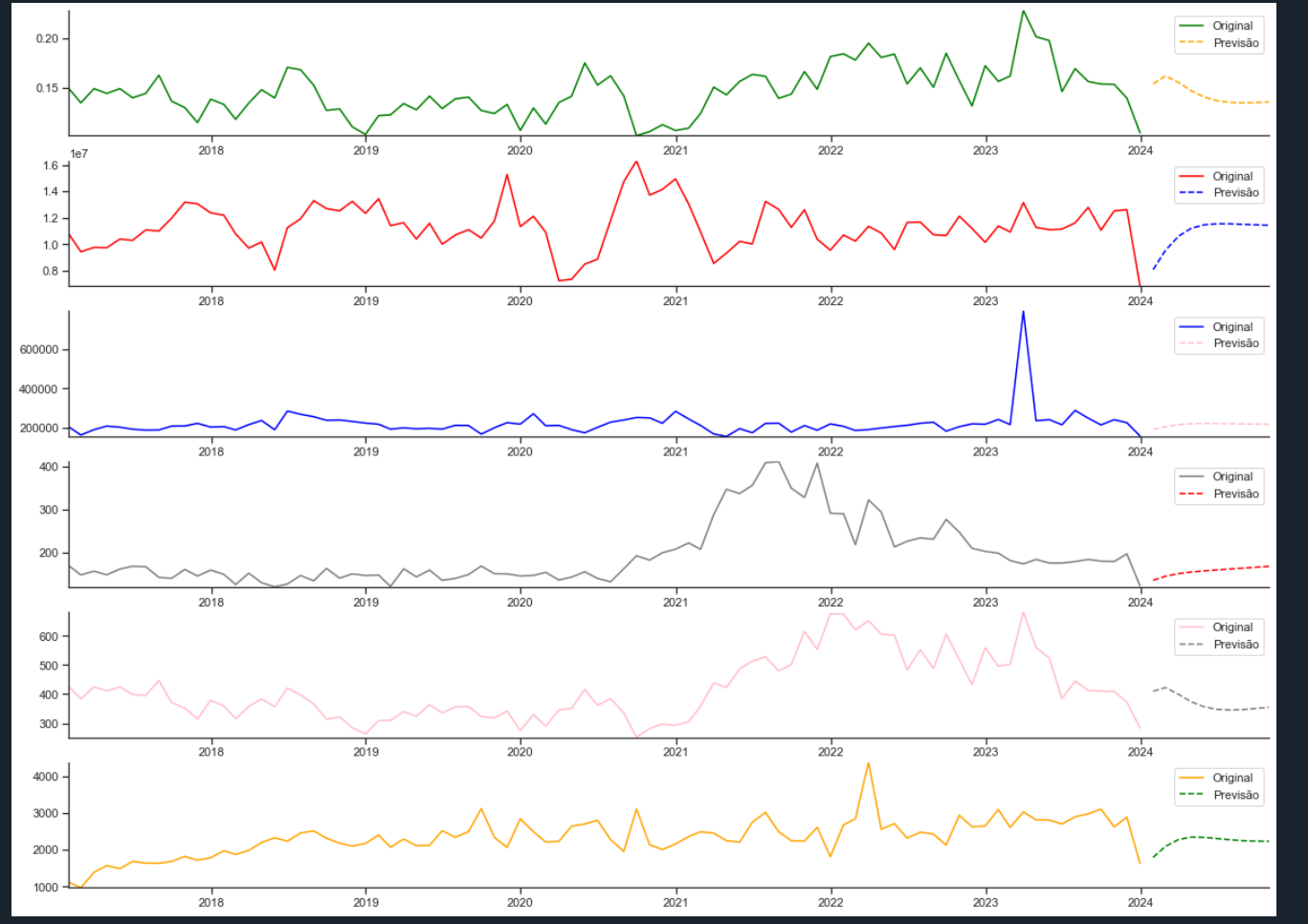
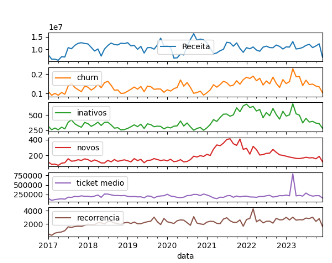
segue abaixo o código:
# O código a seguir para criar um dataframe e remover as linhas duplicadas sempre é executado e age como um preâmbulo para o script:
# dataset = pandas.DataFrame(data, Receita, churn, inativos, novos, ticket medio, recorrencia)
# dataset = dataset.drop_duplicates()
# Cole ou digite aqui seu código de script:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from statsmodels.tsa.api import VAR, ARIMA
dados = dataset
dados["data"] = pd.to_datetime(dados["data"])
dados.set_index('data', inplace=True)
media_dia = dados.mean()
dados = dados.fillna(media_dia)
dados_mensal = dados.resample("M").sum()
dados_mensal.isnull().sum()
media = dados_mensal.mean()
dados_substituidos = dados_mensal.fillna(media)
dados_substituidos.rolling(12).mean().plot(subplots=True)
dados_substituidos.diff().plot(subplots=True)
dados_substituidos.plot(subplots=True)
plt.show()
model = VAR(dados_substituidos)
model_fitted = model.fit()
print(model_fitted.summary())
lag_order = model_fitted.k_ar
forecast = model_fitted.forecast(model_fitted.endog, steps=10)
# Criar um DataFrame para armazenar as previsões
forecast_index = pd.date_range(start=dados_substituidos.index[-1] + pd.Timedelta(weeks=1), periods=10, freq='M')
forecast_df = pd.DataFrame(forecast, index=forecast_index, columns=dados_substituidos.columns)
fig, axes = plt.subplots(nrows=6, ncols=1, figsize=(20, 15))
colunas = dados_substituidos.columns.tolist()
cores = ["green", "red", "blue", "gray", "pink", "orange"]
cores2 = ["orange", "blue", "pink", "red", "gray", "green"]
for i, coluna in enumerate(colunas):
# Use Matplotlib diretamente para criar os gráficos
axes[i].plot(dados_substituidos.index, dados_substituidos[coluna], color=cores[i], label="Original")
axes[i].plot(forecast_df.index, forecast_df[coluna], color=cores2[i], linestyle='--', label='Previsão')
# Ajuste as escalas dos eixos conforme necessário
axes[i].set_xlim([dados_substituidos.index[0], forecast_df.index[-1]])
axes[i].set_ylim([min(dados_substituidos[coluna].min(), forecast_df[coluna].min()),
max(dados_substituidos[coluna].max(), forecast_df[coluna].max())])
# Adicione a legenda para cada subplot
axes[i].legend()
# Remova as linhas de grade para todos os subgráficos
for ax in axes:
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
# Exiba o gráfico
plt.show()

