import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans, AgglomerativeClustering
from sklearn.decomposition import PCA
from scipy.cluster.hierarchy import dendrogram, linkage
iris = load_iris()
df = pd.DataFrame(
iris.data,
columns=iris.feature_names
)
df["species"] = iris.target
df["species"] = df["species"].map({
0: "setosa",
1: "versicolor",
2: "virginica"
})
print("Primeiras linhas do dataset:")
print(df.head())
print("\nInformações gerais:")
print(df.info())
print("\nEstatísticas descritivas:")
print(df.describe())
X = df.drop("species", axis=1)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("\nDados padronizados com sucesso!")
kmeans = KMeans(
n_clusters=3,
random_state=42,
n_init=10
)
clusters_kmeans = kmeans.fit_predict(X_scaled)
df["Cluster_KMeans"] = clusters_kmeans
print("\nResultado K-Means:")
print(df[["species", "Cluster_KMeans"]].head())
hierarchical = AgglomerativeClustering(
n_clusters=3
)
clusters_hierarchical = hierarchical.fit_predict(X_scaled)
df["Cluster_Hierarchical"] = clusters_hierarchical
print("\nResultado Hierarchical Clustering:")
print(df[["species", "Cluster_Hierarchical"]].head())
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
print("\nVariância explicada pelos componentes principais:")
print(pca.explained_variance_ratio_)
print(
f"\nVariância total explicada: "
f"{sum(pca.explained_variance_ratio_):.2%}"
)
plt.figure(figsize=(8, 6))
plt.scatter(
X_pca[:, 0],
X_pca[:, 1],
c=clusters_kmeans
)
plt.title("K-Means com PCA")
plt.xlabel("Componente Principal 1")
plt.ylabel("Componente Principal 2")
plt.show()
plt.figure(figsize=(8, 6))
plt.scatter(
X_pca[:, 0],
X_pca[:, 1],
c=clusters_hierarchical
)
plt.title("Hierarchical Clustering com PCA")
plt.xlabel("Componente Principal 1")
plt.ylabel("Componente Principal 2")
plt.show()
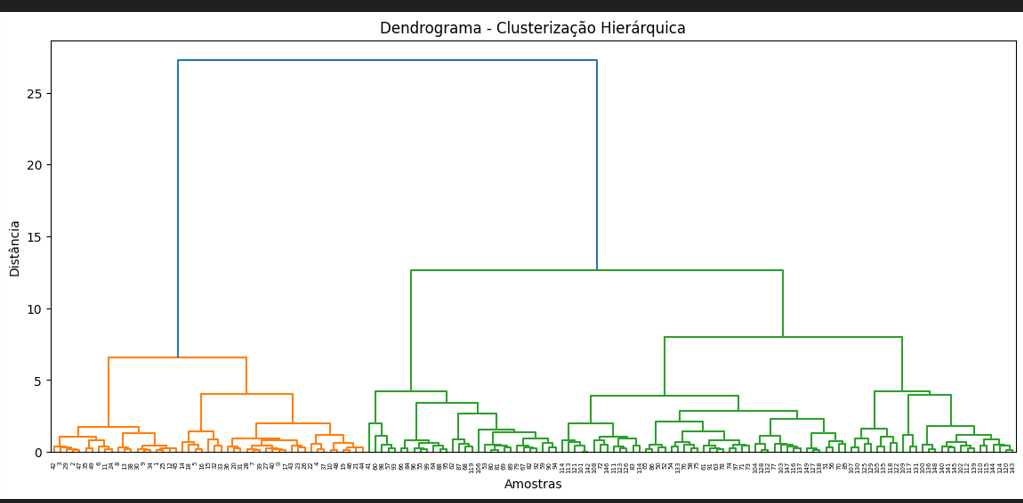
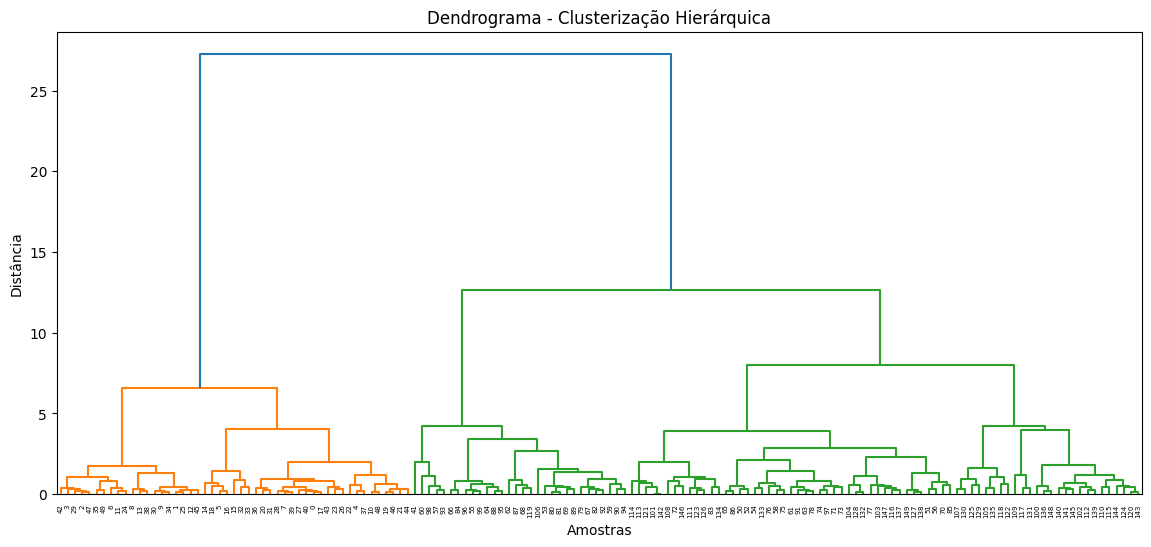
linked = linkage(
X_scaled,
method="ward"
)
plt.figure(figsize=(14, 6))
dendrogram(linked)
plt.title("Dendrograma - Clusterização Hierárquica")
plt.xlabel("Amostras")
plt.ylabel("Distância")
plt.show()
print("\nDistribuição dos clusters K-Means:")
print(df["Cluster_KMeans"].value_counts())
print("\nDistribuição dos clusters Hierárquicos:")
print(df["Cluster_Hierarchical"].value_counts())
print("\nTabela final:")
print(df.head())
print("\nAnálise concluída com sucesso!")
print(
"Foram aplicadas técnicas de K-Means, "
"Hierarchical Clustering e PCA ao dataset Iris."
)

 )
)