
Olá, estou tentando fazer a extração de dados dessa API: https://www.balldontlie.io/#get-all-stats com o seguinte código em python:
import requests
import json
import time
resultados_totais = []
paginas_totais_para_ler = int(11000)
contador_extra = 0
for page_num in range(1, paginas_totais_para_ler + 1):
url = "https://balldontlie.io/api/v1/stats?per_page=100&page=" + str(page_num)
print("Lendo", url)
response = requests.get(url)
data = response.json()
response.raise_for_status()
resultados_totais = resultados_totais + data['data']
contador_extra = contador_extra + 1
print(contador_extra)
if contador_extra == 59:
contador_extra = 0
print('tempo')
time.sleep(60)
print("Temos um total de", len(resultados_totais), "resultados")
with open('test.json', 'w', encoding='utf-8') as d:
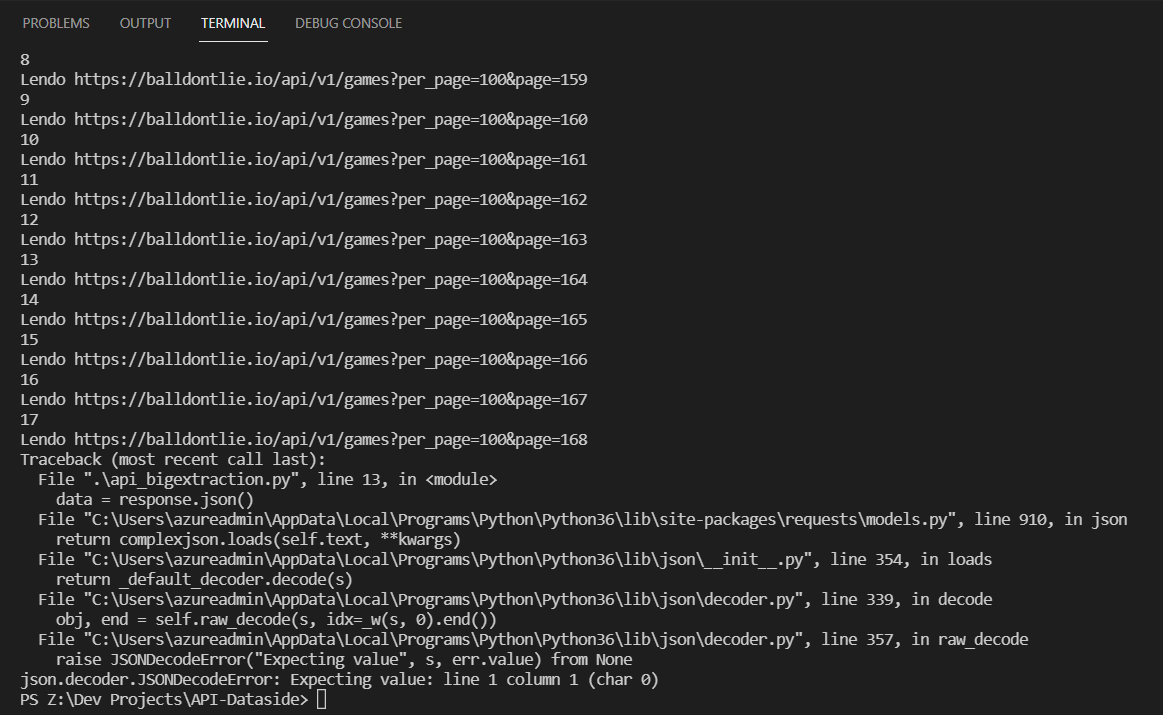
json.dump(resultados_totais, d, ensure_ascii=False, indent=4)Porém, sempre obtenho esse erro: (https://cdn1.gnarususercontent.com.br/1/292460/5c2858ca-33df-4bd8-9b44-0d50a48ab3e0.png)
A API deveria suportar 60 requests por segundo, as vezes até passa de 60, mas no final sempre dá esse erro. Alguém teria alguma sugestão para poder me ajudar?
OBS: Preciso dos dados de todas as 11000 páginas do 'stats'

{kind=link}