Dá erro quando conecto no Chroma Db e não encontra o modelo intfloat/multilingual-e5-large
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Dá erro quando conecto no Chroma Db e não encontra o modelo intfloat/multilingual-e5-large


Se você está usando o Chroma com embeddings personalizados (ex: Hugging Face Transformers), o modelo precisa estar disponível localmente ou acessível via internet.
Soluções possíveis:
Baixar manualmente o modelo:
pip install transformers
from transformers import AutoTokenizer, AutoModel
model_name = "intfloat/multilingual-e5-large"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
Isso baixa e armazena o modelo no cache local de Hugging Face.
Verifique se há problemas de conexão ou permissão, especialmente se estiver rodando em ambiente restrito (e.g. offline, servidor corporativo, docker sem internet).
Localmente ele funciona
Falta de acesso à internet no ambiente remoto: • O modelo precisa ser baixado da Hugging Face na primeira vez. • Se o ambiente está offline, ele não conseguirá fazer isso.
verifica se esta logado em todos os ambientes e configurados corretamente

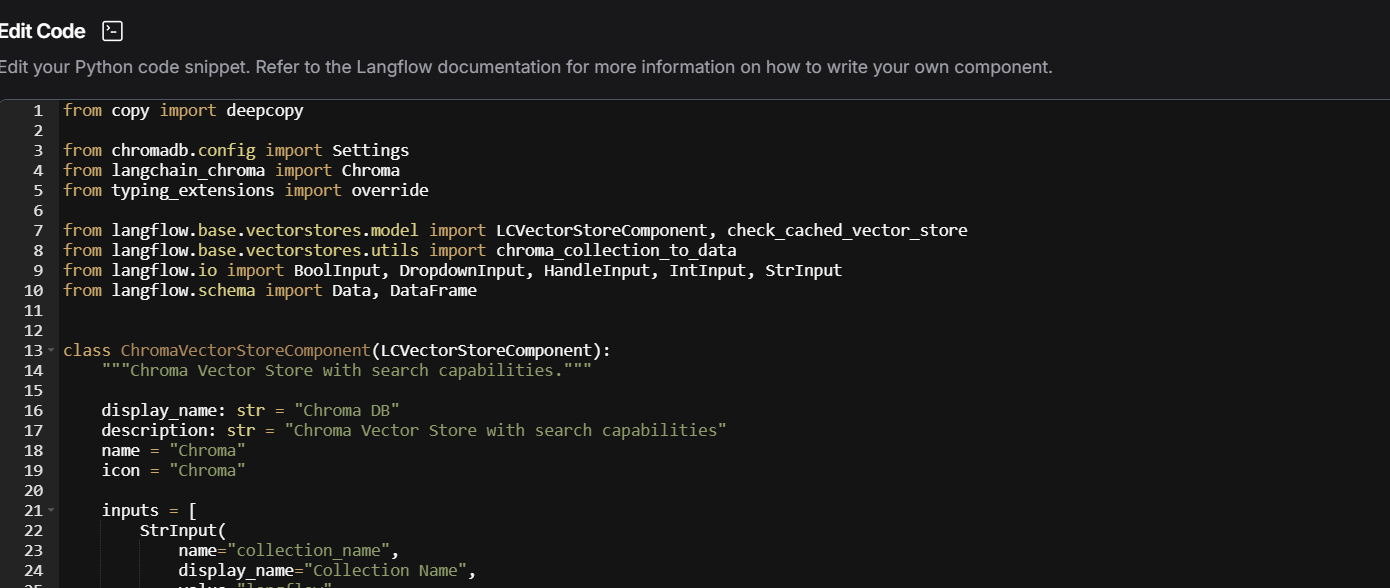
from copy import deepcopy
from chromadb.config import Settings
from langchain_chroma import Chroma
from typing_extensions import override
from langflow.base.vectorstores.model import LCVectorStoreComponent, check_cached_vector_store
from langflow.base.vectorstores.utils import chroma_collection_to_data
from langflow.io import BoolInput, DropdownInput, HandleInput, IntInput, StrInput
from langflow.schema import Data, DataFrame
class ChromaVectorStoreComponent(LCVectorStoreComponent):
"""Chroma Vector Store with search capabilities."""
display_name: str = "Chroma DB"
description: str = "Chroma Vector Store with search capabilities"
name = "Chroma"
icon = "Chroma"
inputs = [
StrInput(
name="collection_name",
display_name="Collection Name",
value="langflow",
),
StrInput(
name="persist_directory",
display_name="Persist Directory",
advanced=True,
info="Leave empty for in-memory mode (recommended for Hugging Face Spaces)",
),
*LCVectorStoreComponent.inputs,
HandleInput(name="embedding", display_name="Embedding", input_types=["Embeddings"]),
BoolInput(
name="allow_duplicates",
display_name="Allow Duplicates",
advanced=True,
info="If false, will not add documents that are already in the Vector Store.",
),
DropdownInput(
name="search_type",
display_name="Search Type",
options=["Similarity", "MMR"],
value="Similarity",
advanced=True,
),
IntInput(
name="number_of_results",
display_name="Number of Results",
info="Number of results to return.",
advanced=True,
value=10,
),
IntInput(
name="limit",
display_name="Limit",
advanced=True,
info="Limit the number of records to compare when Allow Duplicates is False.",
),
]
@override
@check_cached_vector_store
def build_vector_store(self) -> Chroma:
"""Builds the Chroma object."""
try:
from chromadb import Client, PersistentClient
from langchain_chroma import Chroma
except ImportError as e:
msg = "Could not import Chroma integration package. Please install it with `pip install langchain-chroma chromadb`."
raise ImportError(msg) from e
try:
# Configuração simplificada
if self.persist_directory:
self.log("Warning: Persistence may not work properly in Hugging Face Spaces")
persist_directory = self.resolve_path(self.persist_directory)
client = PersistentClient(path=persist_directory)
else:
# Modo em memória (recomendado para Spaces)
client = Client()
chroma = Chroma(
client=client,
embedding_function=self.embedding,
collection_name=self.collection_name,
)
self._add_documents_to_vector_store(chroma)
self.status = chroma_collection_to_data(chroma.get(limit=self.limit))
return chroma
except Exception as e:
self.log(f"Error building Chroma: {str(e)}")
raise
def _add_documents_to_vector_store(self, vector_store: "Chroma") -> None:
"""Adds documents to the Vector Store."""
ingest_data: list | Data | DataFrame = self.ingest_data
if not ingest_data:
self.status = ""
return
# Convert DataFrame to Data if needed using parent's method
ingest_data = self._prepare_ingest_data()
stored_documents_without_id = []
if self.allow_duplicates:
stored_data = []
else:
stored_data = chroma_collection_to_data(vector_store.get(limit=self.limit))
for value in deepcopy(stored_data):
del value.id
stored_documents_without_id.append(value)
documents = []
for _input in ingest_data or []:
if isinstance(_input, Data):
if _input not in stored_documents_without_id:
documents.append(_input.to_lc_document())
else:
msg = "Vector Store Inputs must be Data objects."
raise TypeError(msg)
if documents and self.embedding is not None:
self.log(f"Adding {len(documents)} documents to the Vector Store.")
vector_store.add_documents(documents)
else:
self.log("No documents to add to the Vector Store.")
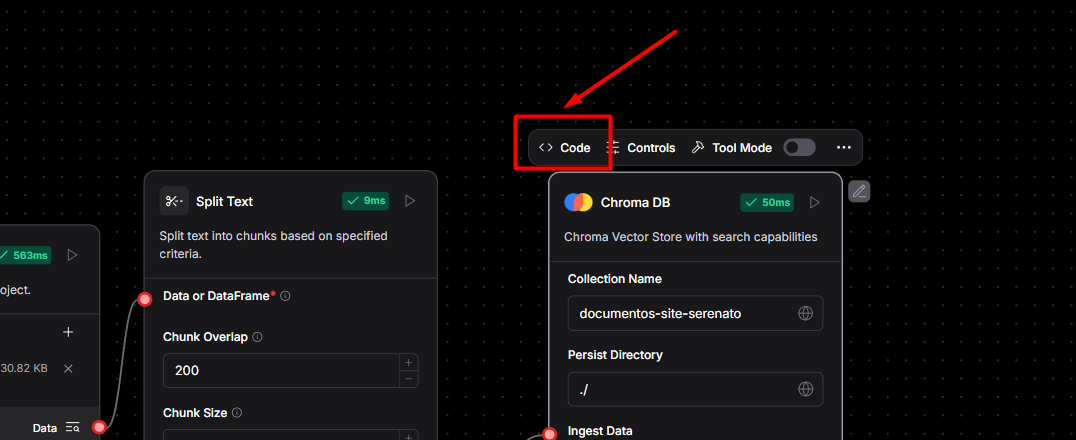
Eu estava tentando configurar um servidor Chroma com host, portas e CORS, o que não é necessário para um uso básico no Hugging Face Spaces. O Hugging Face Spaces tem um sistema de arquivos efêmero, então tentar persistir dados localmente geralmente não funciona. Além disso, não havia tratamento adequado para casos onde a criação do cliente falha. Também observei muitas configurações avançadas que não são relevantes para um ambiente como o Spaces. O código para colocar no code do chorma DB esta logo acima. !o print de onde clicar para inserir o código](https://cdn1.gnarususercontent.com.br/1/883396/e998d5fa-8239-41f8-94bf-9fbcaa9698df.png)
{kind=link}