Ao tentar utilizar o comando para deploy da service, o mesmo fica preso em uma etapa e não termina a execução. Esperei até 30 minutos e não avança além desta etapa.

Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Ao tentar utilizar o comando para deploy da service, o mesmo fica preso em uma etapa e não termina a execução. Esperei até 30 minutos e não avança além desta etapa.


Olá Matheus! Tudo bem?
Pelo que entendi, você está tentando utilizar o comando para deploy da service, mas está enfrentando um problema em que a execução fica presa em uma etapa e não avança. Isso pode ser um pouco frustrante, mas vamos tentar encontrar uma solução para você.
Uma possível causa para esse problema pode ser a falta de recursos na sua instância da AWS. Você pode tentar aumentar a capacidade da sua instância ou verificar se há algum outro recurso que esteja em uso e possa estar interferindo na execução.
Outra possibilidade é que o comando esteja com algum erro ou inconsistência. Nesse caso, você pode tentar revisar o comando e verificar se todos os parâmetros estão corretos. Também é importante verificar se você tem as permissões necessárias para executar o comando.
Por fim, se nenhuma das soluções acima funcionar, você pode tentar entrar em contato com o suporte da AWS para obter ajuda mais específica para o seu caso.
Espero ter ajudado e bons estudos!

Estou com o mesmo problema.
Outra possibilidade é que o comando esteja com algum erro ou inconsistência. Nesse caso, você pode tentar revisar o comando e verificar se todos os parâmetros estão corretos. Também é importante verificar se você tem as permissões necessárias para executar o comando.
Para confirmar que não era algum problema com o meu código, baixei os fontes da aula direto do github, fazendo clone do repositório git@github.com:alura-cursos/2625-alurafood-ms-infra-aws.git
Segui o passo-a-passo e mesmo assim no deploy do Service fica preso indefinidamente.
Uma possível causa para esse problema pode ser a falta de recursos na sua instância da AWS. Você pode tentar aumentar a capacidade da sua instância ou verificar se há algum outro recurso que esteja em uso e possa estar interferindo na execução.
Tentei com os valores abaixo:
Valores originais do código do Github cpu: 512 memoryLimitMiB: 1024
Aumentei para ver se funcionava cpu: 1024 memoryLimitMiB: 2048
Abaixo segue a classe com o ócdigo original do Service baixado da aula.
public AluraServiceStack(final Construct scope, final String id, final StackProps props, final Cluster cluster) {
super(scope, id, props);
Map<String, String> autenticacao= new HashMap<>();
autenticacao.put("SPRING_DATASOURCE_URL", "jdbc:mysql://" + Fn.importValue("pedidos-db-endpoint") + ":3306/alurafood-pedidos?createDatabaseIfNotExist=true");
autenticacao.put("SPRING_DATASOURCE_USERNAME", "admin");
autenticacao.put("SPRING_DATASOURCE_PASSWORD", Fn.importValue("pedidos-db-senha"));
IRepository iRepository = Repository.fromRepositoryName(this, "repositorio", "img-pedidos-ms");
ApplicationLoadBalancedFargateService aluraService = ApplicationLoadBalancedFargateService.Builder.create(this, "AluraService")
.serviceName("alura-service-ola")
.cluster(cluster) // Required
.cpu(512) // Default is 256
.desiredCount(1) // Default is 1
.listenerPort(8080)
.assignPublicIp(true)
.taskImageOptions(
ApplicationLoadBalancedTaskImageOptions.builder()
.image(ContainerImage.fromEcrRepository(iRepository))
.containerPort(8080)
.containerName("app_ola")
.environment(autenticacao)
.logDriver(LogDriver.awsLogs(AwsLogDriverProps.builder()
.logGroup(LogGroup.Builder.create(this, "PedidosMsLogGroup")
.logGroupName("PedidosMsLog")
.removalPolicy(RemovalPolicy.DESTROY)
.build())
.streamPrefix("PedidosMS")
.build()))
.build())
.memoryLimitMiB(1024) // Default is 512
.publicLoadBalancer(true) // Default is false
.build();
ScalableTaskCount scalableTarget = aluraService.getService().autoScaleTaskCount(EnableScalingProps.builder()
.minCapacity(1)
.maxCapacity(3)
.build());
scalableTarget.scaleOnCpuUtilization("CpuScaling", CpuUtilizationScalingProps.builder()
.targetUtilizationPercent(70)
.scaleInCooldown(Duration.minutes(3))
.scaleOutCooldown(Duration.minutes(2))
.build());
scalableTarget.scaleOnMemoryUtilization("MemoryScaling", MemoryUtilizationScalingProps.builder()
.targetUtilizationPercent(65)
.scaleInCooldown(Duration.minutes(3))
.scaleOutCooldown(Duration.minutes(2))
.build());
}
Painel dos recursos do CloudFormation
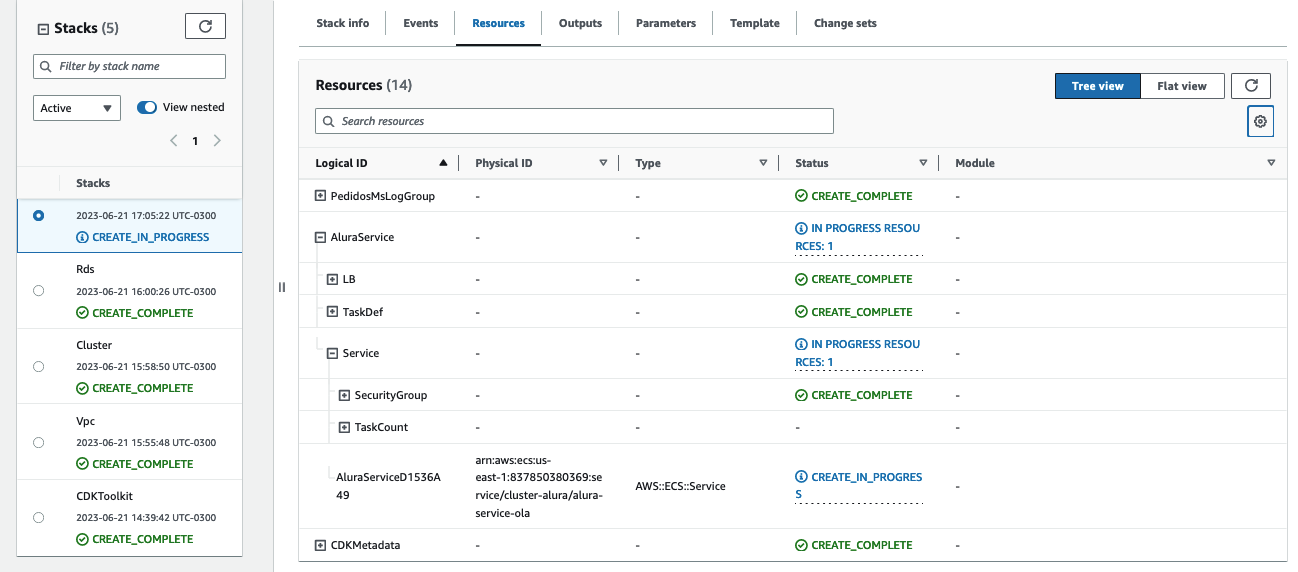
Tentei alterar os parâmetros também e o problema persiste, e acredito que não seja possível entrar em contato com o suporte da aws, visto que o plano que utilizo é gratuíto e neste plano só permite solicitar suporte para coisas referente a conta e não coisas referentes a suporte técnico.

Olá Matheus, tudo bem? Continua com problemas? Está utilizando a última versão do CDK ?
Hoje resolvi tentar subir novamente para a aws a aplicação e me deparei com o mesmo problema. Ao verificar um pouco mais a fundo o problema consegui identificar que o problema estava no health check. O health check não estava conseguindo verificar a integridade da aplicação e por isso ele ficava preso no estágio 13 com a tarefa subindo e sendo derrubada devido a este problema. Para resolver adicionei a seguinte linha no código da service:
aluraService.getTargetGroup().configureHealthCheck(HealthCheck.builder().port("8080").path("/pedidos").interval(Duration.seconds(30)) // Intervalo entre verificações
.healthyHttpCodes("200-499") // Códigos HTTP que indicam que o serviço está saudável
.unhealthyThresholdCount(2).build());
Ao adicionar esta linha após a criação do ApplicationLoadBalancerFargateService consegui fazer com que todos os containeres subissem.