Olá,
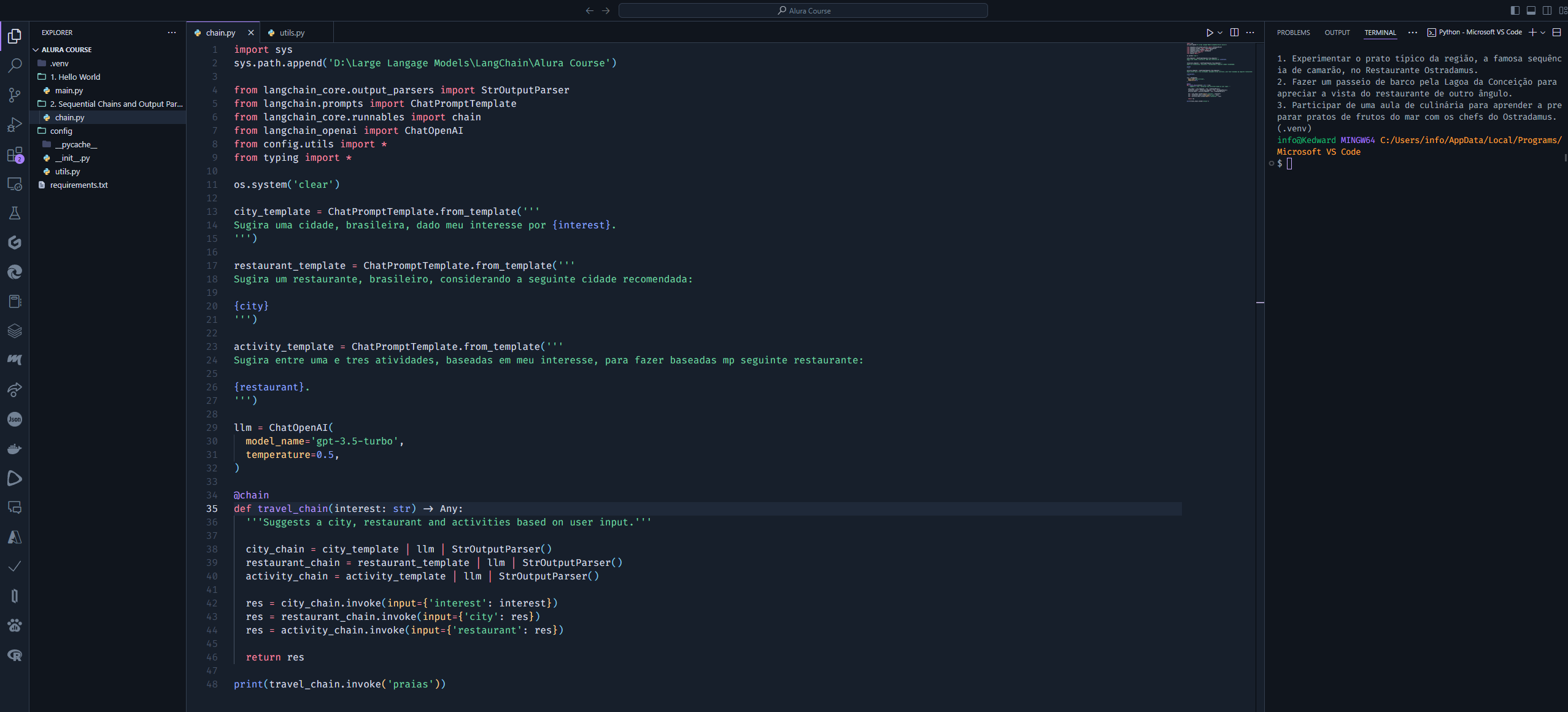
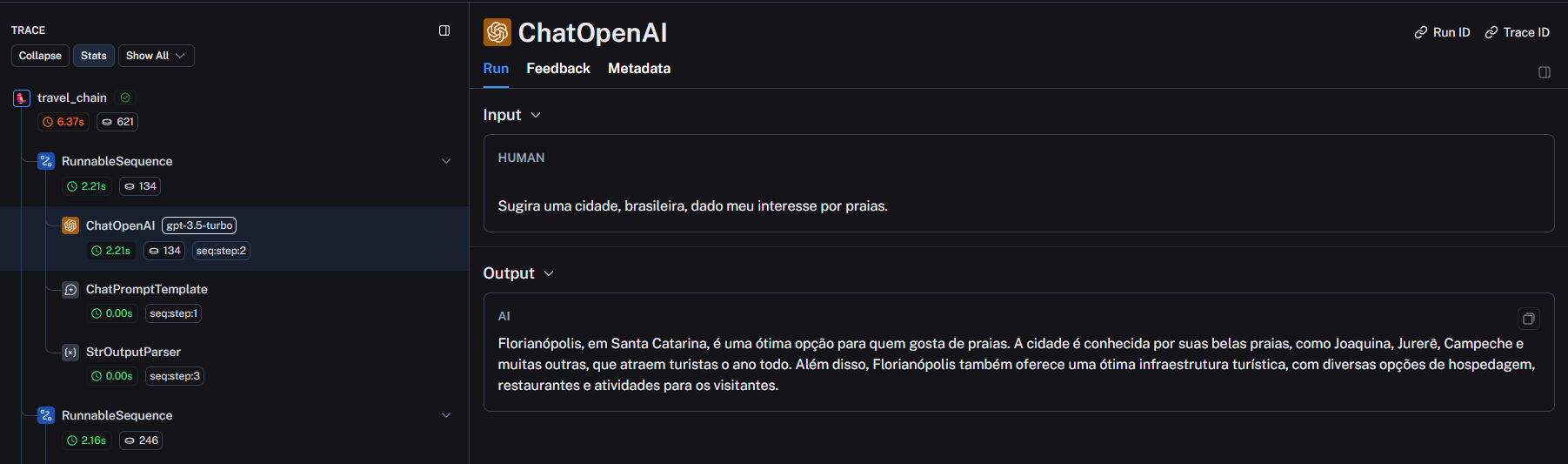
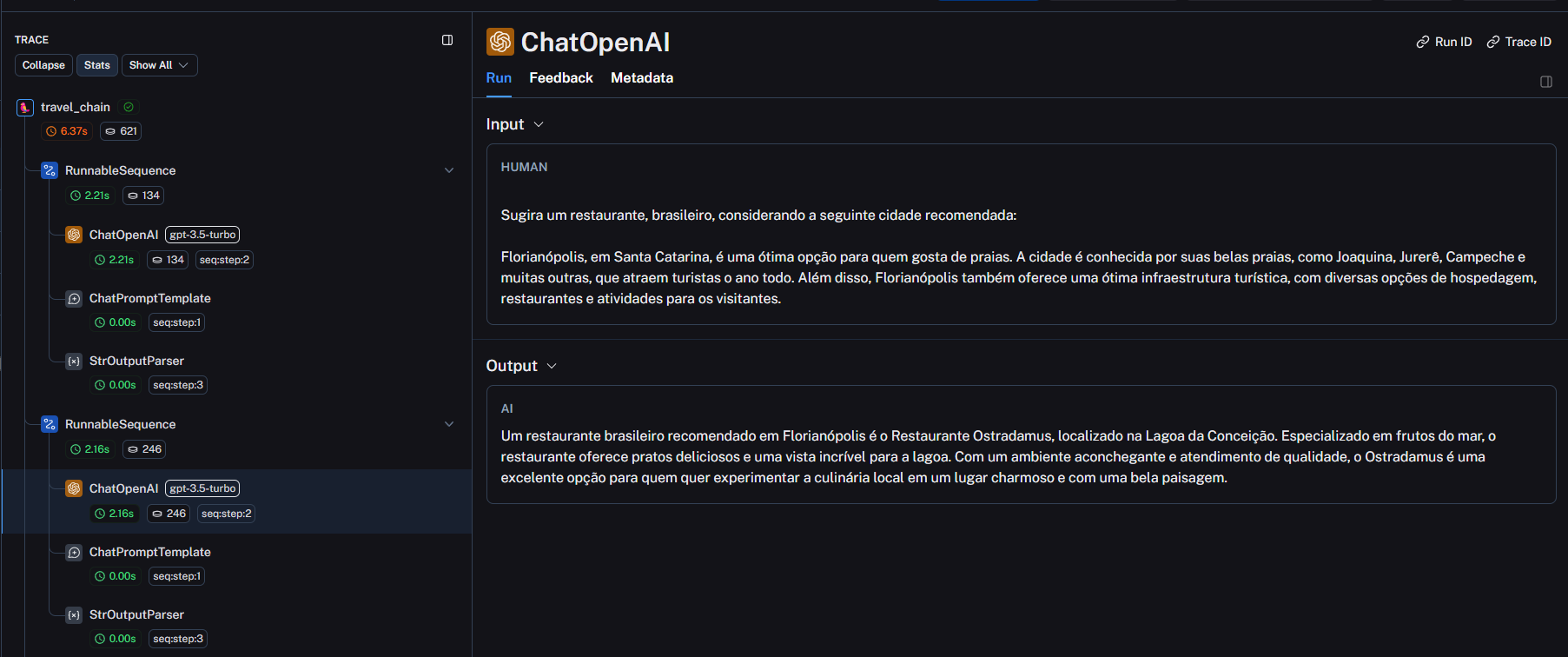
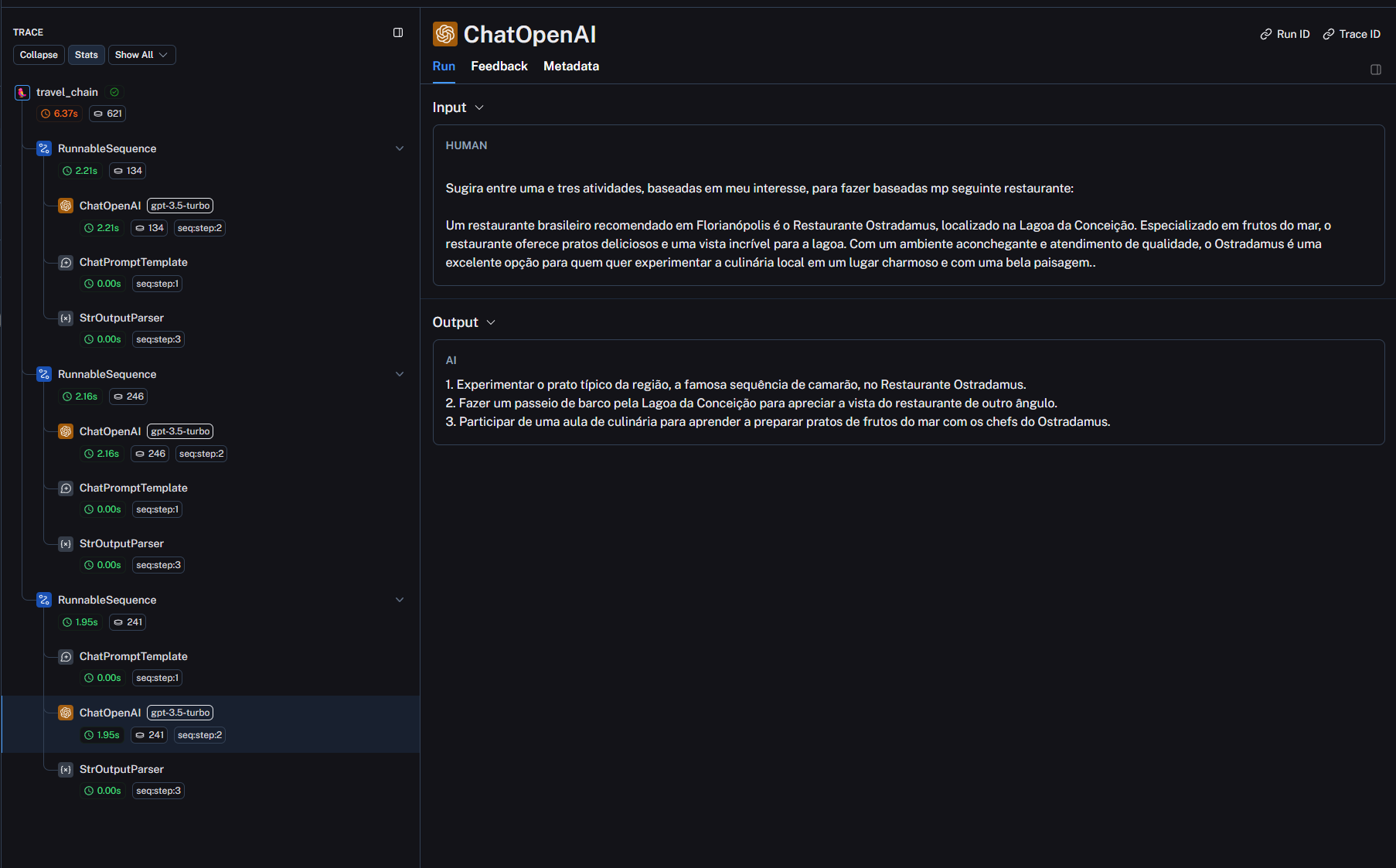
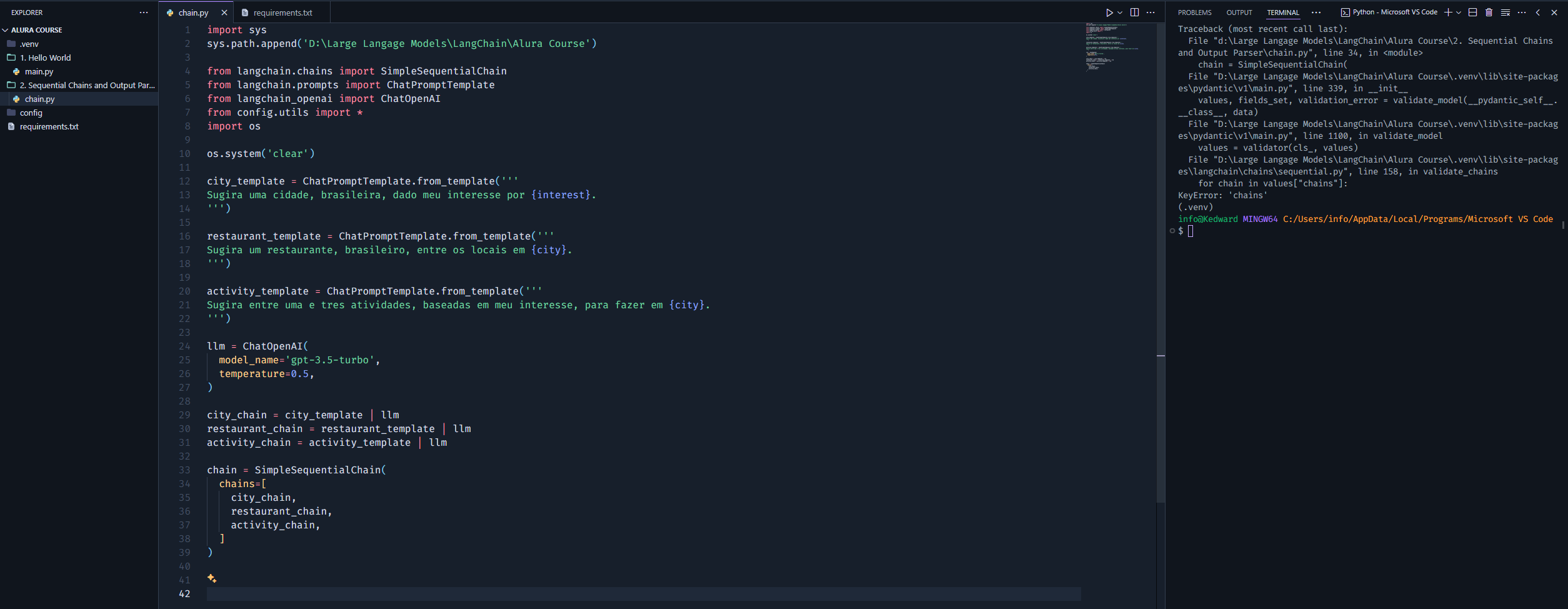
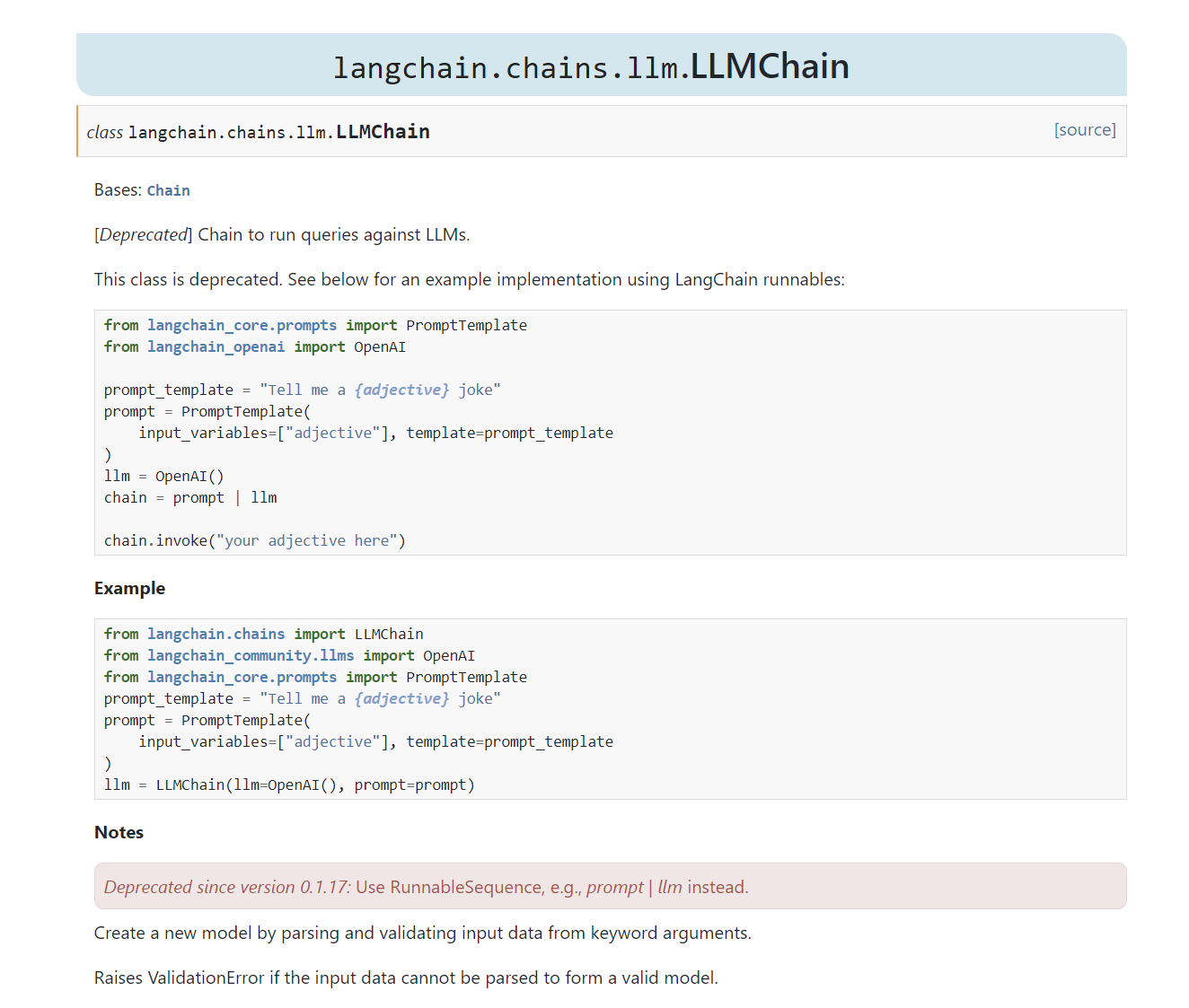
Estou na seguinte aula e não estou conseguindo executar minha cadeia usando SimpleSequentialChain. Notem que não estou utilizando o módulo LLMChain porque, pela documentação, está depreciado - então encurtei as cadeias individuais como recomenda a doc. Ainda assim, não sei se fiz algo errado ou se é algo da biblioteca.
- Imagem do erro
- Imagem da documentação dizendo sobre LLMChain estar depreciado
NOTA:
Abaixo, podem verificar as versões das bibliotecas que estou utilizando:
- Não incluí
python-dotenvporque estou utilizando a variável ambeinteOPENAI_API_KEYno sistema
openai==1.30.4
langchain==0.2.1
langchain-openai==0.1.8