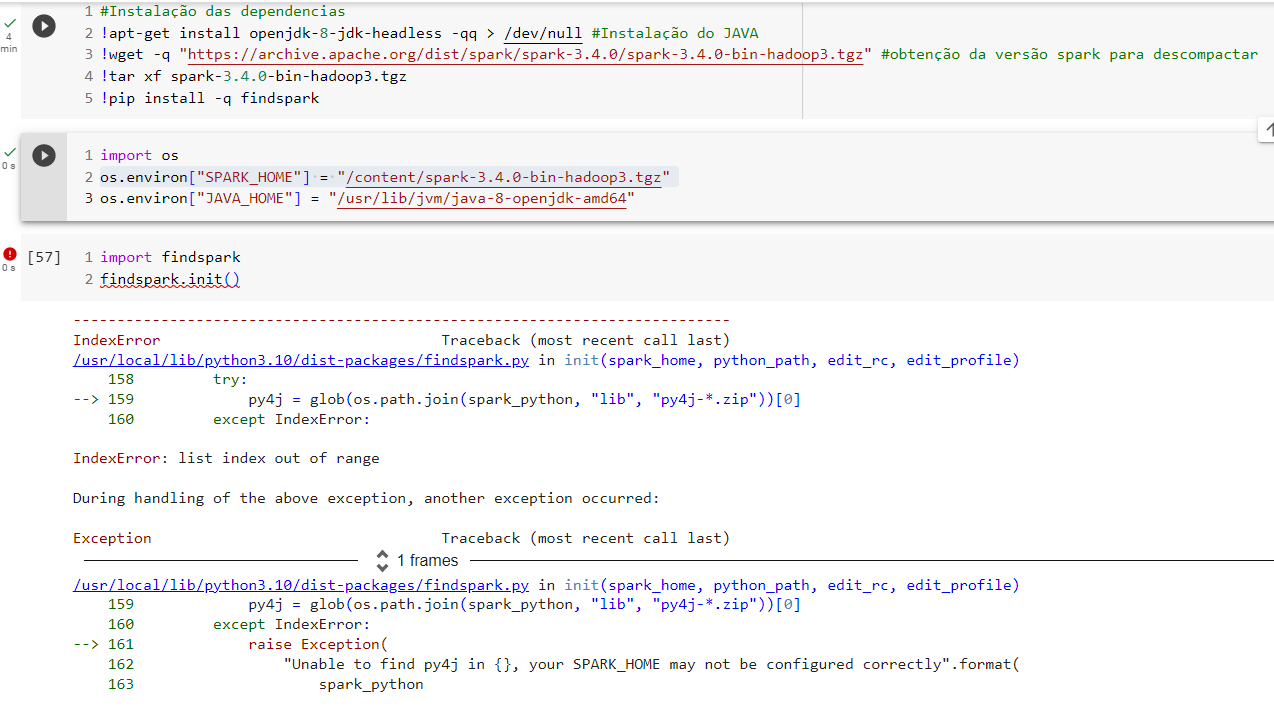
Já conferi todos os links mas toda as vezes que rodo a findspark.init() acusa o erro da imagem em anexo.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Já conferi todos os links mas toda as vezes que rodo a findspark.init() acusa o erro da imagem em anexo.


Olá Priscila, tudo bem com você?
Peço desculpas pela demora em obter um retorno.
Esse erro geralmente ocorre quando a variável SPARK_HOME não está configurada corretamente, seja por caminho inválido, falta de arquivos, dentre outros. Porém, observei que em seu código você está utilizando a versão 3.4.0 do Spark e o Hadoop na versão 3, porém, no curso o instrutor utiliza as seguintes versões:
| Ferramenta | Versão |
|---|---|
| Spark | 3.1.2 |
| Hadoop | 2.7 |
Sendo assim, peço que utilize as versões semelhantes à aula para melhorar aproveitando e acompanhamento do curso, para isso, reinicie o ambiente de execução do colab clicando no menu superior na opção "Ambiente de Execução" -> "Reiniciar Ambiente de Execução" e após isso, digite as seguintes células:
# instalar as dependências
!apt-get update -qq
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!wget -q https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop2.7.tgz
!tar xf spark-3.1.2-bin-hadoop2.7.tgz
!pip install -q findspark
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.1.2-bin-hadoop2.7"
import findspark
findspark.init()
Espero ter ajudado. Continue mergulhando em conhecimento e não hesite em voltar ao fórum para continuar aprendendo e interagindo com a comunidade.
Em caso de dúvidas estou à disposição.
Abraços e bons estudos!