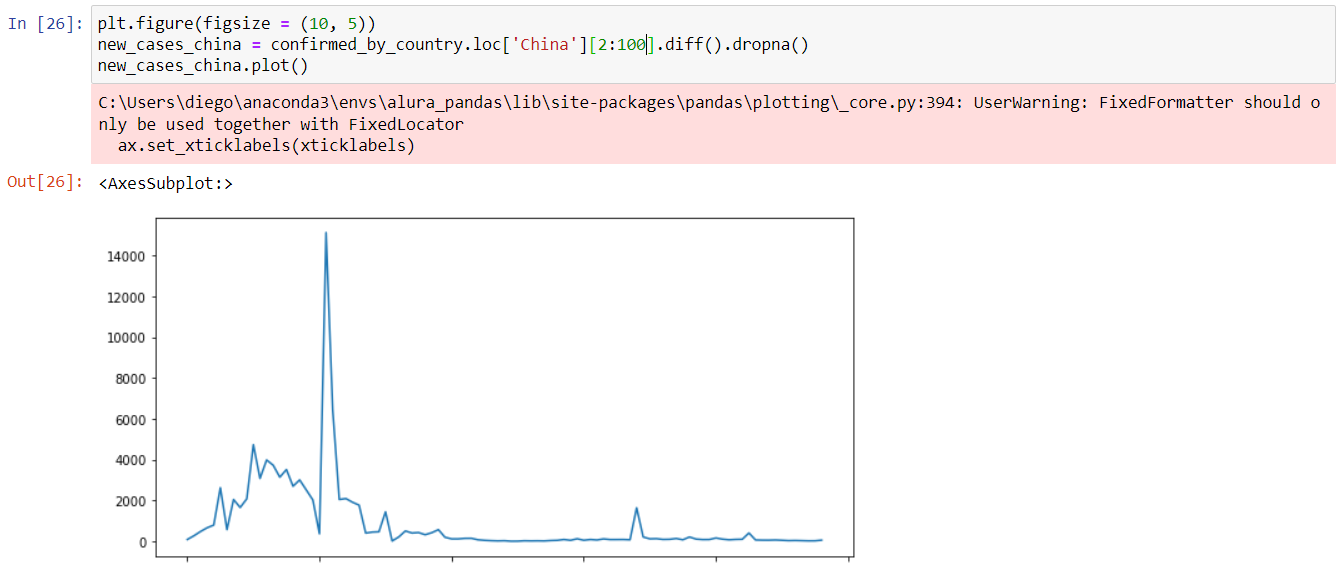
Olá, Monalisa! De fato: deve ser devido a versão do Python/Anaconda. Em outros gráficos plotados, o eixo X exibiu normalmente os valores dos "ticks". A versão do ambiente que estou utilizando é diferente, então certamente haverá algumas incongruências. Agradeço desde já e aproveito, sem querer abusar da boa vontade, para lhe pedir ajuda em outra questão:
Na aula 3 do curso, foi utilizado um dataset contido no seguinte link:
https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv
Porém, ao utilizar o last_date (como sugerido no curso) a coluna referente a letalidade (que foi criada também na aula 3) ficará zerada, pois não há dados referentes a esse período. Mas ao analisar determinada Series de um país aleatório, é possível notar que há recuperados nesse meio, o que compromete o cálculo de letalidade. Entendo que o exemplo do curso é diferente, pois o dataset continuou a ser atualizado após a publicação do curso.
Seria válido realizar uma modificação e utilizar apenas o recorte que contenha dados? Ou isso poderia prejudicar o andamento do curso? Alguma sugestão de como proceder em relação a isso? Obrigado.