
Boa tarde!!
Tenho que fazer uma tarefa aqui no trabalho, mas estou quebrando a cabeça e não consigo sair do lugar. As iterações dentro do pandas e do numpy não fazem muito sentido para mim, ou eu ainda não peguei elas nem 10%.
Eu tenho o seguinte df, que é apenas um exemplo (alguns dados foram excluidos pois são confidenciais):
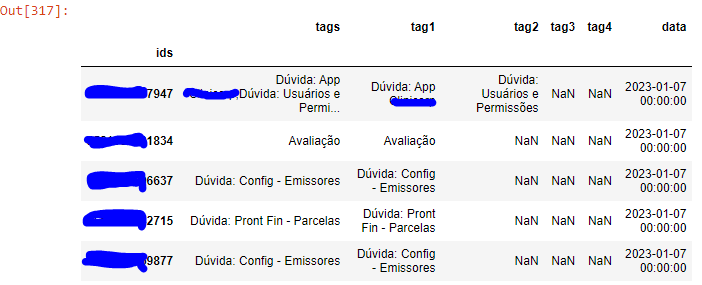
Eu preciso fazer o seguinte:
- Pegar o primeiro ID dessa lista.
- Roda a lista toda procurando pelo mesmo ID, e ao encontrar ele precisa verificar se esse ID existe com as datas de hoje e de ontem .
- Caso não, passar para o próximo ID.
- Caso sim, verificar se alguma das TAGs bate uma com a outra.
- Caso sim, criar um novo campo que receba "Sim"
- Caso não, passar para o próximo ID e criar um novo campo que receba "Não"
Eu não consigo criar a lógica para fazer isso rodar.
Eu crio uma lista com os IDs únicos e faço um for nessa lista? Mas ao mesmo tempo eu já vi que não deveria fazer for pois o pandas não é feito pra isso. Deveria usar o NumPy e utilizar vetorização, mas eu fico babando ao tentar entender tudo isso.
Eu já consegui criar essa lógica no excel, mas fica tudo muito manual e gostaria de automatizar, agilizar o processo.
Algum gênio do pandas/numpy/python pode me ajudar? Gracias!

