Notei nessa aula que, ao utilizar 'range', por exemplo o código baixo:
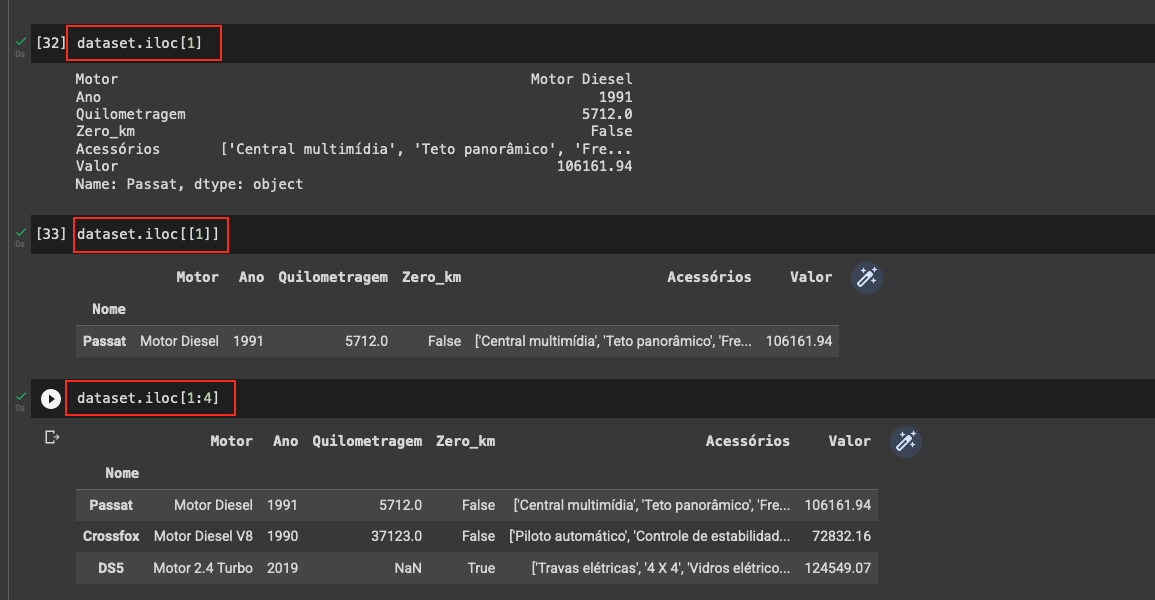
dataset.iloc[1:4]O retorno é em formato DataFrame mesmo utilizando apenas um par de colchetes [ ] , diferente de quando selecionamos items específicos que requerem o duplo colchete [[ ]]:
dataset.iloc[1]dataset.iloc[[1]]Também notei que ao tentar usar mais de um item com apenas um par de colchetes [ ] tenho diferentes resultados:
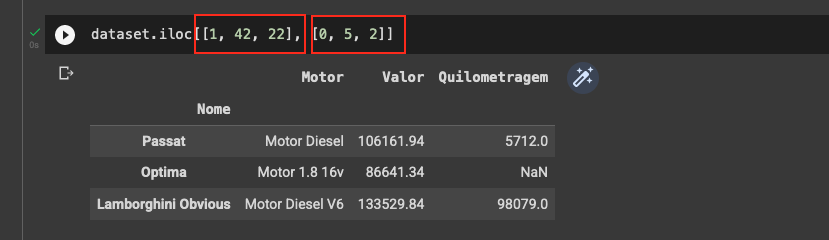
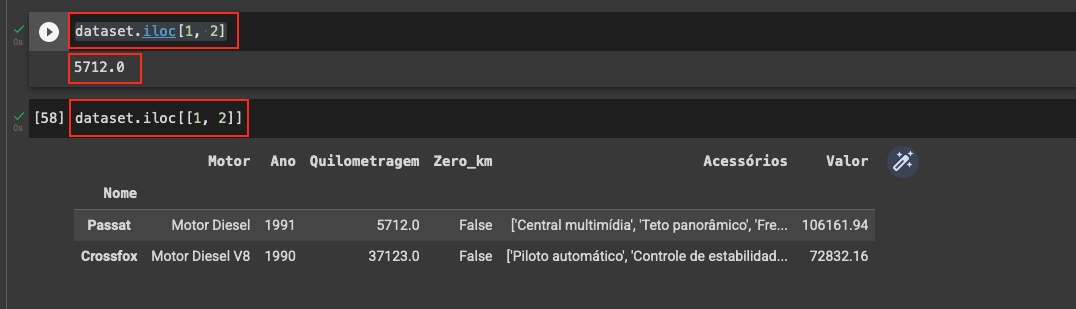
- Usando 2 itens, obtenho um número o qual não entendo o resultado:
dataset.iloc[1, 2]>>
5712.0- Usando 3 ou mais números, obtenho o erro:
dataset.iloc[1, 2, 3]>>
---------------------------------------------------------------------------
IndexingError Traceback (most recent call last)
<ipython-input-49-9e3bd352d59e> in <module>
----> 1 dataset.iloc[1, 2, 3]
3 frames
/usr/local/lib/python3.8/dist-packages/pandas/core/indexing.py in _validate_key_length(self, key)
790 def _validate_key_length(self, key: Sequence[Any]) -> None:
791 if len(key) > self.ndim:
--> 792 raise IndexingError("Too many indexers")
793
794 def _getitem_tuple_same_dim(self, tup: tuple):
IndexingError: Too many indexersCom relação a seleção de range 'automaticamente' gerar um DataFrace, acredito que o Panda 'entende' que temos uma range com múltiplos item, ou bidimencional e automaticamente gera o DataFrame, porém não compreendo os cenários acima.