Olá, Victor! Tudo bom?
Bastante interessante o modo como utilizou o groupby com o cumcount, eu refatorei um pouco do código por aqui e cheguei em um resultado que satisfaz o pedido.
Antes de começarmos, uma dica importante na hora de postar o código por aqui no Fórum é postar utilizando o bloco de código e também disponibilizar alguma amostra dos dados. No artigo Fórum da Alura são motradas algumas dicas de como usar melhor nosso Fórum.
Utilizando a sua metodologia cheguei nesse resultado:
import pandas as pd
import numpy as np
df = pd.DataFrame({'col1':[10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
'col2':['a','a','b','c','c','b','d','d','d','d']})
df['teste'] = df['col2'] + ["_"]*len(df['col2']) + (df.groupby('col2').cumcount() + 1).astype(str)
df
Saída:
| col1 | col2 | teste |
|---|
| 0 | 10 | a | a_1 |
| 1 | 20 | a | a_2 |
| 2 | 30 | b | b_1 |
| 3 | 40 | c | c_1 |
| 4 | 50 | c | c_2 |
| 5 | 60 | b | b_2 |
| 6 | 70 | d | d_1 |
| 7 | 80 | d | d_2 |
| 8 | 90 | d | d_3 |
| 9 | 100 | d | d_4 |
Mas enquanto verificava essa questão, também desenvolvi um procedimento usando Numpy, Pandas e Python.
Criando o DataFrame
import pandas as pd
import numpy as np
df = pd.DataFrame({'col1':[10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
'col2':['a','a','b','c','c','b','d','d','d','d']})
df
Saída:
| col1 | col2 |
|---|
| 0 | 10 | a |
| 1 | 20 | a |
| 2 | 30 | b |
| 3 | 40 | c |
| 4 | 50 | c |
| 5 | 60 | b |
| 6 | 70 | d |
| 7 | 80 | d |
| 8 | 90 | d |
| 9 | 100 | d |
Criando um DataFrame auxiliar
Esse DataFrame foi criado como uma cópia ordenada do primeiro DataFrame, onde nós vamos ordenar pela coluna de interesse, nesse caso, a col2.
df2 = df.sort_values(by='col2')
Criando a lista de contagem
A partir desse momento, eu uso o DataFrame auxiliar para criar uma lista que usa a quantidade de ocorrências dos valores na coluna para numerar cada ocorrência.
reference = df['col2'].value_counts(ascending=True)
reference
Saída:
a 2
b 2
c 2
d 4
Name: col2, dtype: int64
E como agora temos a frequência de cada valor, podemos criar uma lista que vai de 1 até a quantidade de cada elemento.
value_reference = []
for i in reference:
value_reference += list(range(1, i + 1))
value_reference
>>> [1, 2, 1, 2, 1, 2, 1, 2, 3, 4]
E nesse momento, nós podemos adicionar algum caractere entre os termos, um espaço ou sublinhado (_).
value_reference = [" " + str(x) for x in value_reference]
value_reference
>>> [' 1', ' 2', ' 1', ' 2', ' 1', ' 2', ' 1', ' 2', ' 3', ' 4']
Concatenando com Numpy
A partir desse moento, nós podemos usar o método to_list() do Pandas para transformar uma coluna em uma lista, e concatenar com a nossa lista value_reference utilizando uma função do Numpy que concatena strings termo a termo, no caso, a np.char.add(lista1, lista2). Da seguinte maneira:
df2['new_col'] = np.char.add(df2['col2'].to_list(), value_reference)
df2
| col1 | col2 | new_col |
|---|
| 0 | 10 | a | a 1 |
| 1 | 20 | a | a 2 |
| 2 | 30 | b | b 1 |
| 5 | 60 | b | b 2 |
| 3 | 40 | c | c 1 |
| 4 | 50 | c | c 2 |
| 6 | 70 | d | d 1 |
| 7 | 80 | d | d 2 |
| 8 | 90 | d | d 3 |
| 9 | 100 | d | d 4 |
Nesse momento nós podemos voltar a configuração original resetando o nosso índice.
df2.sort_index()
| col1 | col2 | new_col |
|---|
| 0 | 10 | a | a 1 |
| 1 | 20 | a | a 2 |
| 2 | 30 | b | b 1 |
| 3 | 40 | c | c 1 |
| 4 | 50 | c | c 2 |
| 5 | 60 | b | b 2 |
| 6 | 70 | d | d 1 |
| 7 | 80 | d | d 2 |
| 8 | 90 | d | d 3 |
| 9 | 100 | d | d 4 |
Resumo da Ópera
Existem várias maneiras de fazer a mesma coisa utilizando as bibliotecas ou Python puro. Algumas vezes serão necessárias a reescrita do código manualmente para evitar a dependência de bibliotecas externas, mas conhecer as possibilidades de cada ferramenta é essencial para evitar reinventar a roda quando não necessário.

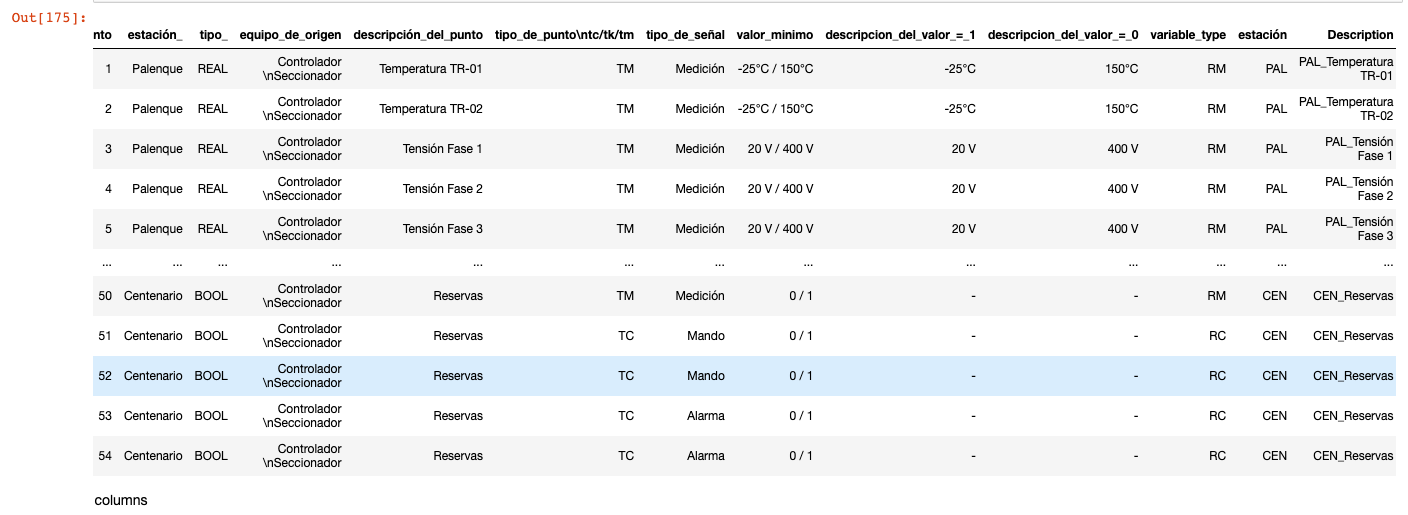
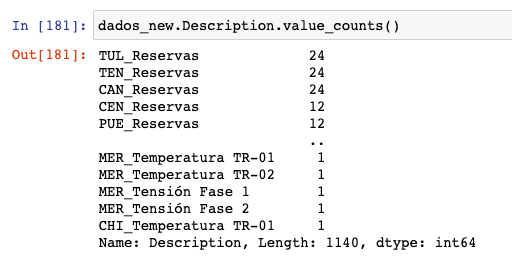 Vocês poderiam me ajudar a tratar essa coluna?
Vocês poderiam me ajudar a tratar essa coluna?