Boa tarde!
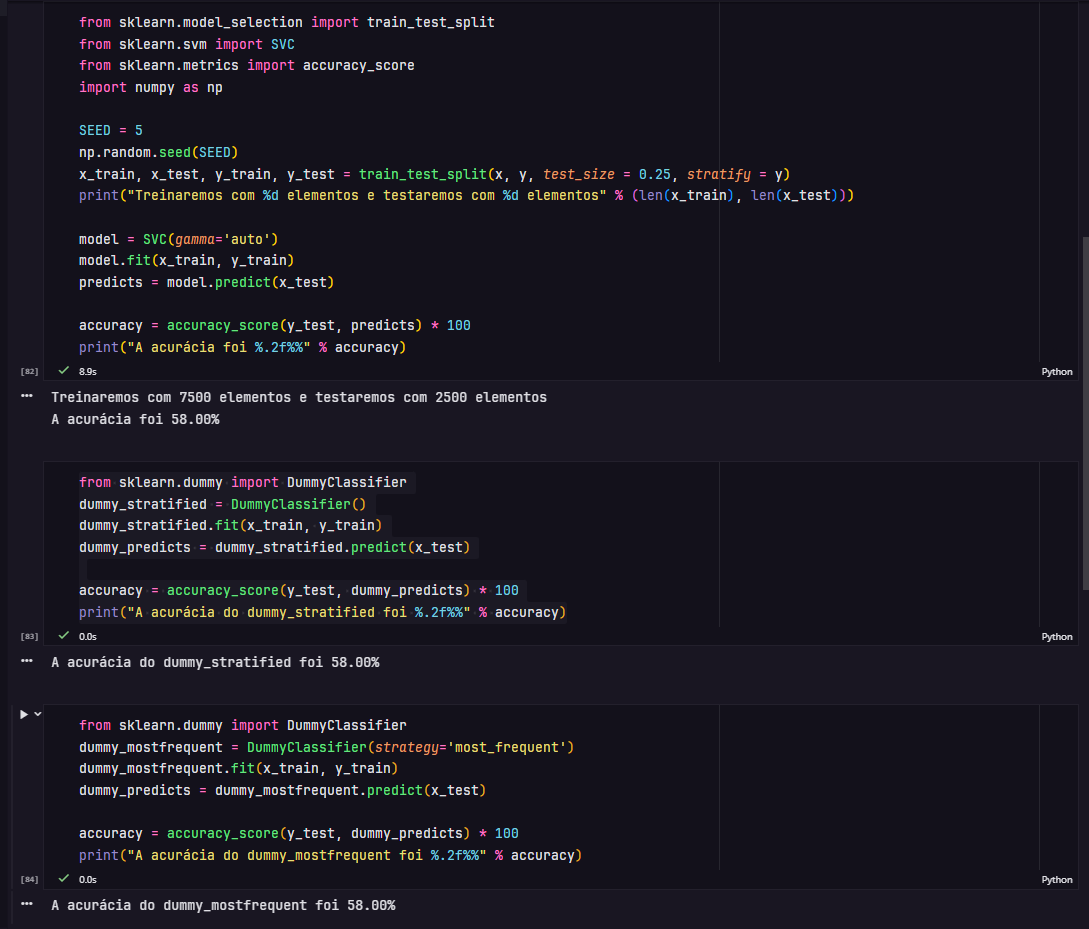
O modelo criado com o SVC e o dummy estão dando a mesma acuracia, até mesmo com as estratégias do dummy diferentes (most_frequent e stratified). Alguma explicação possível pra isso? (Por sinal, parece que nessa aula o professor copia e cola o código, muda o nome do stratified para mostfrequent mas não coloca o "strategy" como parametro no construtor do DummyClassifier)