Prezados, escrevi o seguinte código:
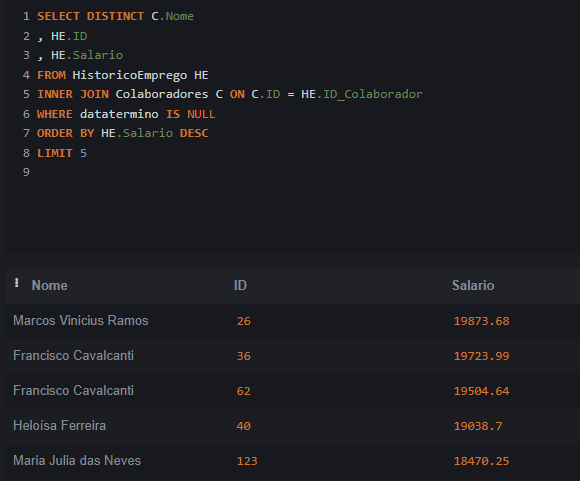
Minha intenção era trazer nomes distintos, uma vez que retornou 2 vezes o colaborador Francisco Cavalcanti com ID diferente.
Como posso realizar o código para não repetir apenas o nome?
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Prezados, escrevi o seguinte código:
Minha intenção era trazer nomes distintos, uma vez que retornou 2 vezes o colaborador Francisco Cavalcanti com ID diferente.
Como posso realizar o código para não repetir apenas o nome?


Olá, Anderson! Como vai?
Para resolver o problema de duplicação de nomes, você pode utilizar a função GROUP BY em vez de DISTINCT. O DISTINCT considera todas as colunas selecionadas, por isso ele não está funcionando como esperado no seu caso. O GROUP BY agrupa os resultados por uma ou mais colunas.
→ Vou deixar abaixo um exemplo de como você pode modificar sua consulta:
SELECT C.Nome, MIN(HE.ID) AS ID, MAX(HE.Salario) AS Salario
FROM HistoricoEmprego HE
INNER JOIN Colaboradores C ON C.ID = HE.ID_Colaborador
WHERE datatermino IS NULL
GROUP BY C.Nome
ORDER BY Salario DESC
LIMIT 5;
→ Explicação:
MIN(HE.ID) e MAX(HE.Salario) são usados para selecionar um ID e o maior salário de cada colaborador.GROUP BY C.Nome agrupa os resultados pelo nome do colaborador, garantindo que cada nome apareça apenas uma vez.ORDER BY Salario DESC ordena os resultados pelo salário em ordem decrescente.LIMIT 5 limita o resultado aos 5 primeiros registros.Desejo sucesso! Continue firme nos estudos! ✨✨