Olá, Guilherme. Tudo bem?
Fique tranquilo, vamos tentar entender o que está acontecendo.
Pergunta 1) Fórmula para remover os outliers:
- o
for está sendo utilizando para passarmos por cada tipo de grupo, ou seja, por Apartamento, Casa, Casa de Condomínio etc; - a variável
eh_tipo serve para fazermos uma seleção de dados contendo apenas os dados que são iguais ao tipo de grupo, ou seja, a cada iteração, teremos uma seleção diferente, onde uma será para Apartamento, outra pra Casa, e assim em diante; - a variável
eh_dentro_limite também serve para guardar uma seleção de dados, porém, agora queremos saber se os valores dos nossos dados não são Outliers, ou seja, nem muito baixos, nem muito altos. Olhando o Box Plot, onde está marcado são, da esquerda pra direita, o limite_inferior e o limite_superior que estão nessa linha de código:
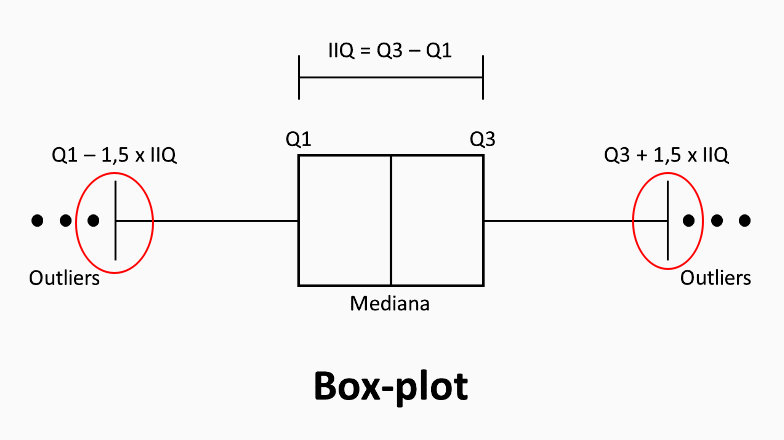
- a variável
selecao serve para guardar uma** seleção de dados** que sejam tanto do tipo que estamos percorrendo (no for) no momento quanto estejam dentro dos limites inferiores e superiores do Box Plot. - por fim, a variável
dados_new serve para guardar a junção dos DataFrames dados_new e dados_selecao.
Pergunta 2) Argumento autopct e coluna Valor no agrupamento por Tipo:
O autopct é um argumento utilizado para especificar como os valores percentuais serão representados no gráfico de pizza (pie). Por exemplo, se você quisesse representar a porcentagem 33.45%, você utilizaria autopct='%1.2f%%, pois o que vem depois do (.) determina a quantidade máxima de casas decimais, que nesse caso são 2. O f diz respeito ao tipo de dado numérico float. Se quiséssemos apenas uma casa decimal, ficaria autopct='%1.1f%%.
Com relação ao Valor estar sendo utilizado no agrupamento, isso acontece porque ele diz respeito à coluna que estamos interessados. Essa coluna serve apenas para vermos os agrupamentos de cada tipo, pois, se não utilizássemos uma coluna específica, veríamos o seguinte:
dados.groupby('Tipo').count()
Saída:
| Bairro | Quartos | Vagas | Suites | Area | Valor | Condominio | IPTU | Valor m2 | Tipo Agregado |
|---|
| Tipo | | | | | | | | | | |
| Apartamento | 8613 | 8613 | 8613 | 8613 | 8613 | 8613 | 8613 | 8613 | 8613 | 8613 |
| Casa | 426 | 426 | 426 | 426 | 426 | 426 | 426 | 426 | 426 | 426 |
| Casa de Condomínio | 454 | 454 | 454 | 454 | 454 | 454 | 454 | 454 | 454 | 454 |
| Casa de Vila | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 | 117 |
| Quitinete | 390 | 390 | 390 | 390 | 390 | 390 | 390 | 390 | 390 | 390 |
Teríamos os mesmos valores para todas as colunas. Então, especificar uma coluna, nesse caso a Valor, nos ajuda a não repetir essas informações:
dados.groupby('Tipo')['Valor'].count()
Saída:
| Tipo | |
|---|
| Apartamento | 8613 |
| Casa | 426 |
| Casa de Condomínio | 454 |
| Casa de Vila | 117 |
| Quitinete | 390 |
| Name: Valor, dtype: int64 | |
O mesmo vale para o Tipo Agregado.
Espero ter ajudado, Guilherme. Se tiver mais alguma dúvida, estou à disposição. Bons estudos =)
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!


