Oi, Enzo, tudo bem?
Desculpe a demora em te responder!
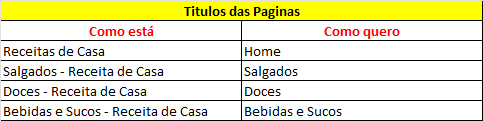
A sintaxe que você utilizou está quase correta. Contudo, podemos realizar alguns ajustes para que a expressão funcione corretamente. Ficaria assim:
CASE
WHEN TITULOS_DAS_PAGINAS = "Receitas de Casa" THEN "Home"
ELSE REGEXP_EXTRACT(TITULOS_DAS_PAGINAS, '([a-z].*?)-')
END
A primeira parte é uma função CASE que verifica se o valor de TITULOS_DAS_PAGINAS é exatamente "Receitas de Casa". Se for o caso, o resultado será "Home". Caso contrário, a expressão avança para a próxima cláusula ELSE, onde será executada a função REGEXP_EXTRACT para extrair uma parte do texto em TITULOS_DAS_PAGINAS que corresponde ao padrão '([a-z].*?)-' .
A expressão regular '([a-z].*?)-' procura por uma sequência que começa com uma letra minúscula [a-z], seguida de qualquer número de caracteres .*? e terminando com um hífen-. Dessa forma, busca-se extrair o texto que vem antes do hífen. Entretanto, há um problema nessa expressão, pois ela só funcionará corretamente se houver um hífen no final do título da página. Se não houver um hífen, a regex não fará uma correspondência e retornará um valor nulo. Isso pode ser resolvido ajustando a expressão regular da seguinte maneira:
CASE
WHEN TITULOS_DAS_PAGINAS = "Receitas de Casa" THEN "Home"
ELSE REGEXP_EXTRACT(TITULOS_DAS_PAGINAS, '([a-z].*?)(?:-|$)')
END
A mudança foi feita na parte '([a-z].*?)(?:-|$)' faz com que haja uma correspondência caso haja um hífen ou não. . Agora, o (?:-|$) representa uma correspondência com um hífen - ou o final da linha $. Dessa forma, mesmo que não haja um hífen no final, ele irá extrair o texto corretamente.
Espero ter ajudado. Caso tenha dúvidas, não hesite em postar no fórum.
Abraços!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!