Gabriela,
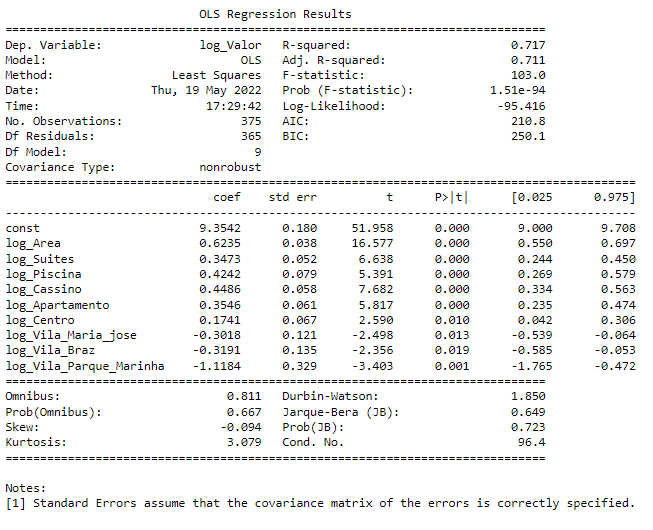
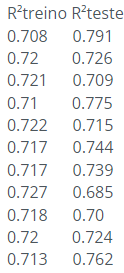
É normal ter variação entre o R quadrado do teste e do treino, isso por causa da amostragem msm, já que essas métricas são calculadas com base nos seus dados.
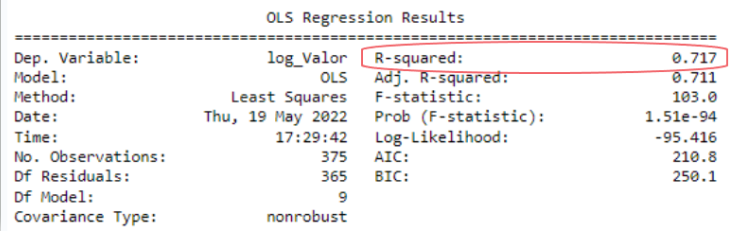
Sobre o quanto seria adequado para o modelo, sinto dizer que não há um consenso na literatura quanto à esse número. Há quem use um conjunto de métricas além do R² para analisar a qualidade do modelo, e também tem quem utiliza a própria interpretação da métrica, ou seja, usando um dos resultados, eu lhe pergunto será que 70% é uma boa métrica para explicabilidade? 70% de 100% parece um bom parâmetro para mim, mas existem casos, por exemplo na saúde, que é preciso adicionar outras variáveis explicativas para aumentar essa métrica.
Em resumo, é normal que o R² seja diferente na amostra do treino e no teste, além disso, não há um ponto específico no R² que diz se é bom ou ruim, isso vai depender da sua análise e do que faz sentido dentro do modelo.
Sei que é um ponto mais abstrato, mas eu espero ter esclarecido um pouco mais.
:)