Quando fui conferir o colab do exercício: "Mão na massa: análise e seleção de modelos de regressão linear" percebi que não houve a divisão entre treino e teste, pegou os dados completos. Eu fiz assim:
hx_train, hx_test, hy_train, hy_test = train_test_split(
dados_hoteis.drop('Preco', axis=1),
dados_hoteis['Preco'],
test_size = 0.3,
random_state = 230
)
df_htrain = pd.DataFrame(hx_train)
df_htrain['Preco'] = hy_train
modelo_h0 = ols(
'Preco ~ ProximidadeTurismo',
data = df_htrain
).fit()
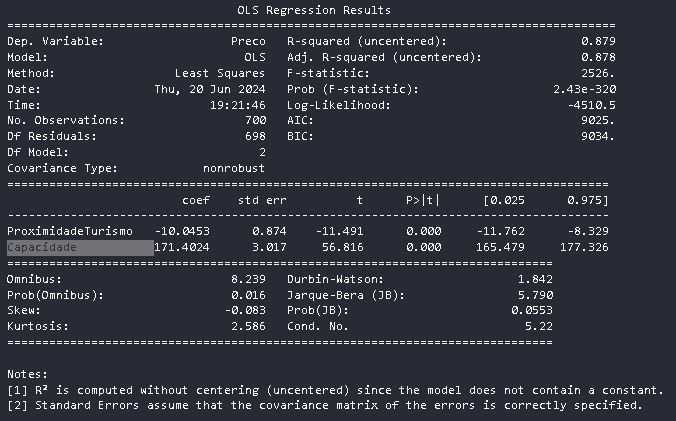
E ai que eu fui fazendo os outros modelos, combinando minhas variáveis e o melhor R2 sem a nota de rodapé de que os dados podem não estar sendo explicado foi o que levou em conta todas as variáveis:
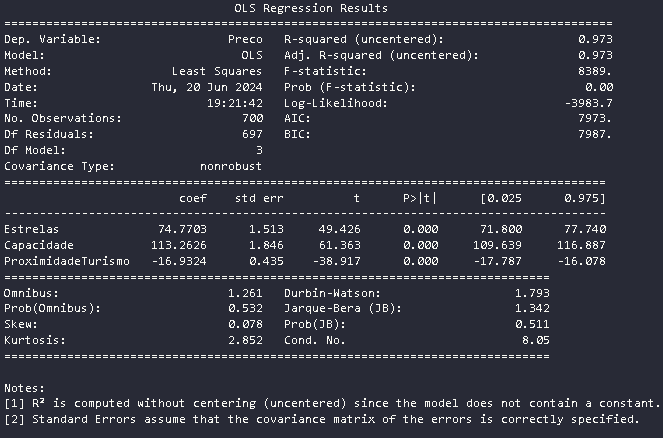
Com isso posso supor que esse é o meu melhor modelo? Segue os outros para comparação: Modelo: Estrelas e Capacidade
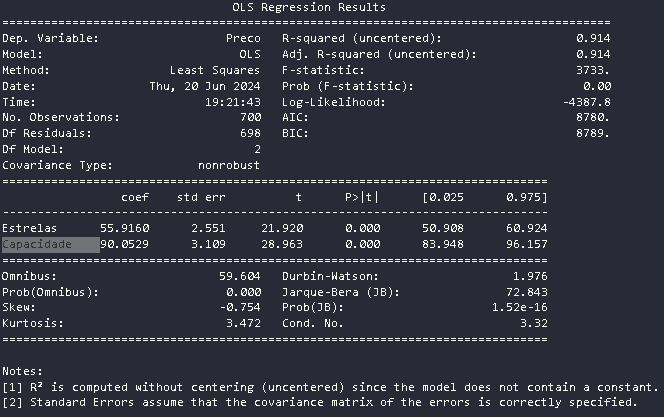
Modelo: ProximidadeTurismo e Estrelas
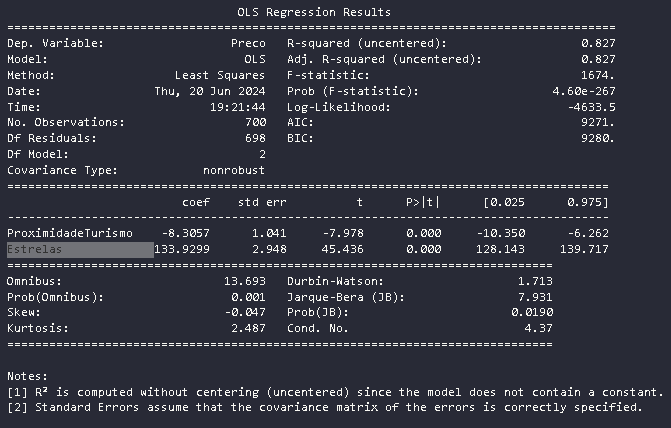
Modelo: ProximidadeTurismo e Capacidade