Eu tenho dificuldade em funções do numpy e em list compreension. Por isso, analisar esse código pra mim é complicado. Eu não consegui entender o que realmente é feito em cada uma dessas linhas.
import numpy as np;
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def backprop(self, x, y):
"""Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def cost_derivative(self, output_activations, y):
"""Return the vector of partial derivatives \partial C_x /
\partial a for the output activations."""
return (output_activations-y)
#### Miscellaneous functions
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))
Extrai esse trecho de código desse link: http://neuralnetworksanddeeplearning.com/chap1.html
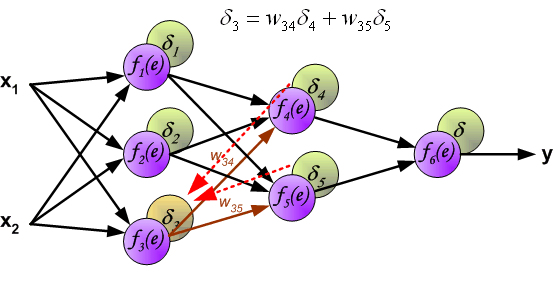
Minha duvida maior esta na função "backprop". A partir da linha onde tem "# backward pass" começa a ficar bem mais dificil de entender. E fica ainda mais dificil de entender o passo a passo desse código, principalmente quando chega na parte desse laço FOR
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
Queria conseguir entender o que esta sendo feito nesses códigos.
Por isso tenho algumas perguntas que gostaria de fazer sobre as linhas do código:
1 - Dentro do método backprop, ao todo, o que o código dessa função faz? O que cada linha dentro da função backprop esta fazendo?
2 - Primeiro: O que esta sendo feito nessas linhas?: "
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
3 - O que esse simbolo "* \" significa no python?
4 - Também, o que esta sendo feito nessas outras linhas?:
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
4 - De acordo com o código da função backprop, que tipo de matrizes a função backprop deve retornar? em qual formato/estrutura?
Por favor, poderiam me explicar em detalhes, passo a passo o que esses códigos fazem? Também, se possivel, poderiam me mostrar outro código equivalente que faça a mesma coisa porém sem usar o numpy e sem usar list compreension? Ficaria mais facil entender.