Olá, Ewelton!
Entendo suas dúvidas e vou tentar esclarecê-las da melhor forma possível.
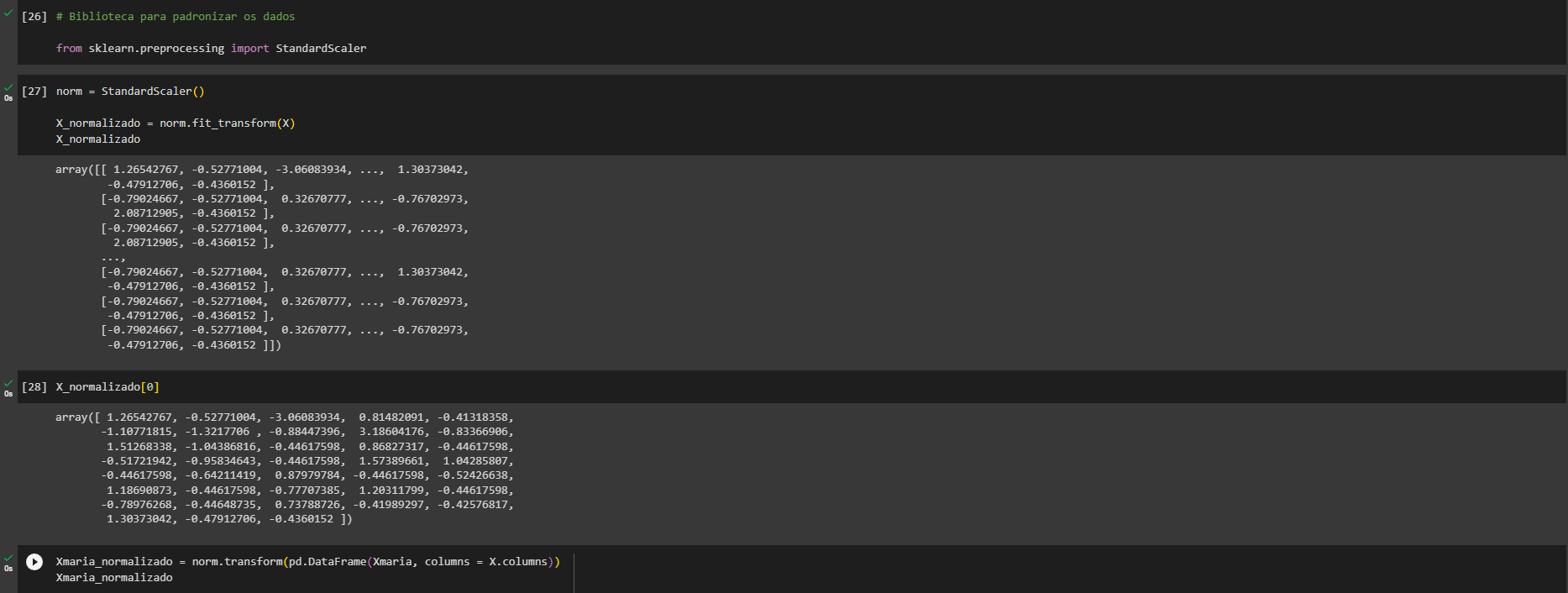
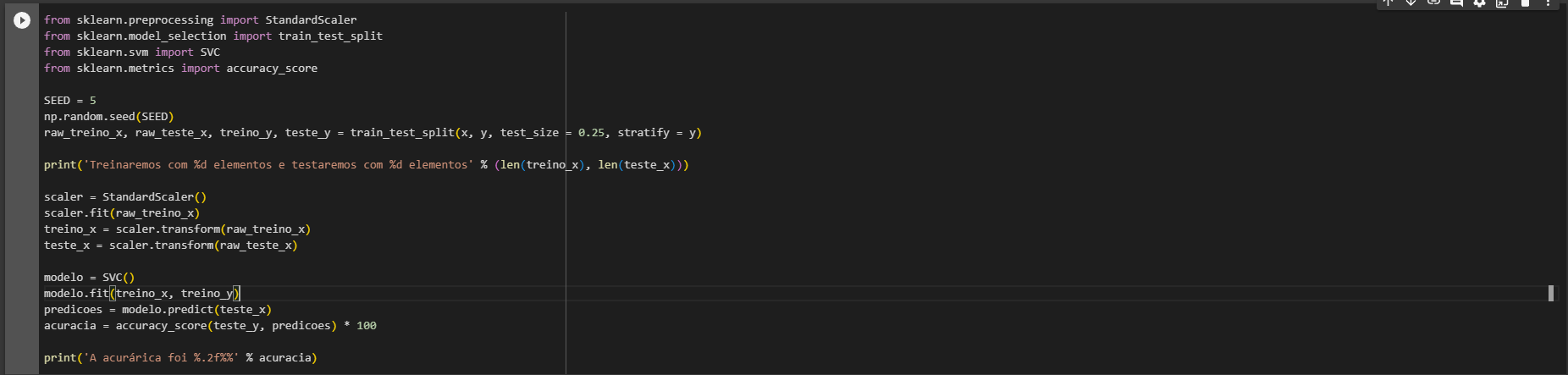
A normalização dos dados é geralmente necessária quando os algoritmos de Machine Learning são sensíveis à magnitude dos dados. Por exemplo, o algoritmo KNN e o SVC (Support Vector Classifier) são baseados em cálculos de distância, então eles são afetados pela escala dos dados. Por outro lado, algoritmos como Decision Trees não são sensíveis à escala dos dados, por isso não precisamos normalizá-los nesse caso.
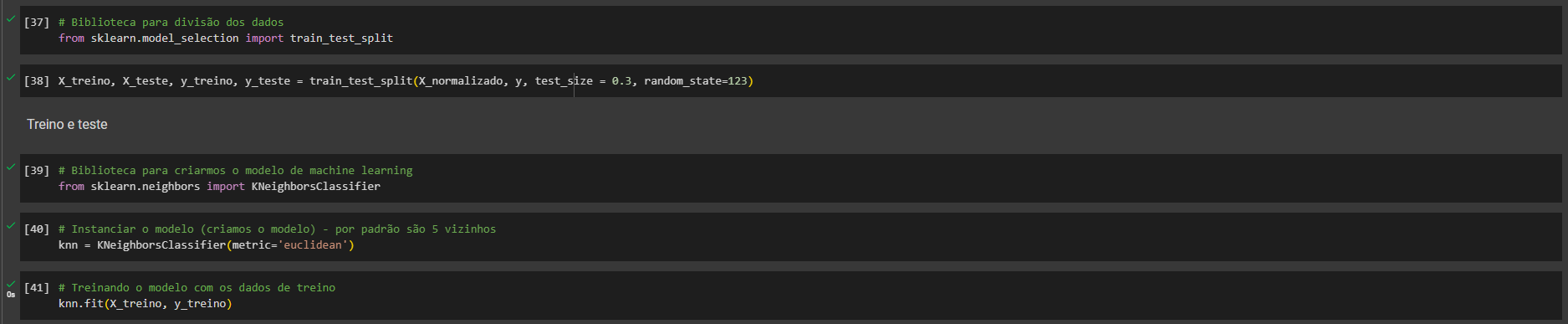
A ordem do pré-processamento e da seleção do modelo pode afetar o resultado, sim. Em geral, é uma boa prática dividir os dados em conjuntos de treinamento e teste antes de qualquer pré-processamento. Isso ocorre porque queremos evitar qualquer vazamento de informação do conjunto de teste para o conjunto de treinamento. No caso do StandardScaler, ele é ajustado ao conjunto de treinamento e, em seguida, é usado para transformar tanto o conjunto de treinamento quanto o de teste. Portanto, primeiro fazemos o train_test_split e depois aplicamos o StandardScaler.
Aparentemente, há uma diferença na ordem dessas etapas nos dois cursos que você mencionou. Isso pode ser devido a diferentes abordagens de ensino ou um erro inadvertido. No entanto, a abordagem correta é a que mencionei acima.
Espero ter ajudado e bons estudos!

 Machine Learning: classificação por trás dos panos
Machine Learning: classificação por trás dos panos