Olá gente!!
Sou muito novo em todo o tópico de data science, analise de dados e programação. Estou adentrando agora no estudo da biblioteca 'pandas'. Dito isso estou tentando me aventurar em algumas analises de banco de dados próprios. Ocorre que, com o VS Code instalado, estou tentando fazer a leitura de um banco de dados, mas só esta sendo voltado para mim o seguinte erro
<>:1: SyntaxWarning: invalid escape sequence '\D'
<>:1: SyntaxWarning: invalid escape sequence '\D'
C:\Users\Usuário\AppData\Local\Temp\ipykernel_14136\1516081637.py:1: SyntaxWarning: invalid escape sequence '\D'
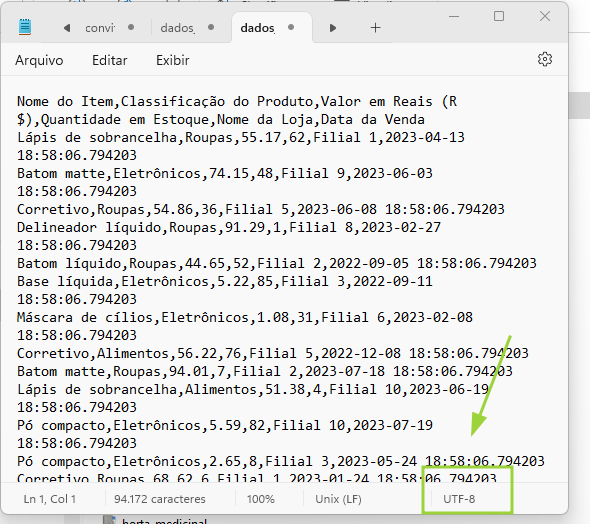
Estatic_crim_tjmg = pd.read_csv('D:/IAGO RODRIGUES\Documents/Estatisticas TJMG/TJMG- Proc Criminal- Geral/TJMG_CN.csv')
C:\Users\Usuário\AppData\Local\Temp\ipykernel_14136\1516081637.py:1: SyntaxWarning: invalid escape sequence '\D'
Estatic_crim_tjmg = pd.read_csv('D:/IAGO RODRIGUES\Documents/Estatisticas TJMG/TJMG- Proc Criminal- Geral/TJMG_CN.csv')
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
Cell In[10], line 1
----> 1 Estatic_crim_tjmg = pd.read_csv('D:/IAGO RODRIGUES\Documents/Estatisticas TJMG/TJMG- Proc Criminal- Geral/TJMG_CN.csv')
File c:\Users\Usuário\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\parsers\readers.py:1026, in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, date_format, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, encoding_errors, dialect, on_bad_lines, delim_whitespace, low_memory, memory_map, float_precision, storage_options, dtype_backend)
1013 kwds_defaults = _refine_defaults_read(
1014 dialect,
1015 delimiter,
(...)
1022 dtype_backend=dtype_backend,
1023 )
1024 kwds.update(kwds_defaults)
-> 1026 return _read(filepath_or_buffer, kwds)
File c:\Users\Usuário\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\parsers\readers.py:620, in _read(filepath_or_buffer, kwds)
617 _validate_names(kwds.get("names", None))
619 # Create the parser.
--> 620 parser = TextFileReader(filepath_or_buffer, **kwds)
622 if chunksize or iterator:
623 return parser
File c:\Users\Usuário\AppData\Local\Programs\Python\Python312\Lib\site-packages\pandas\io\parsers\readers.py:1620, in TextFileReader.__init__(self, f, engine, **kwds)
1617 self.options["has_index_names"] = kwds["has_index_names"]
1619 self.handles: IOHandles | None = None
...
File parsers.pyx:2053, in pandas._libs.parsers.raise_parser_error()
File <frozen codecs>:322, in decode(self, input, final)
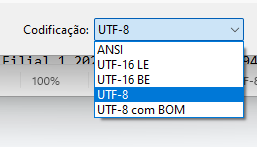
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc1 in position 234: invalid start byte
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
Vocês conseguem me ajudar nisso ? O que estou fazendo de errado ?