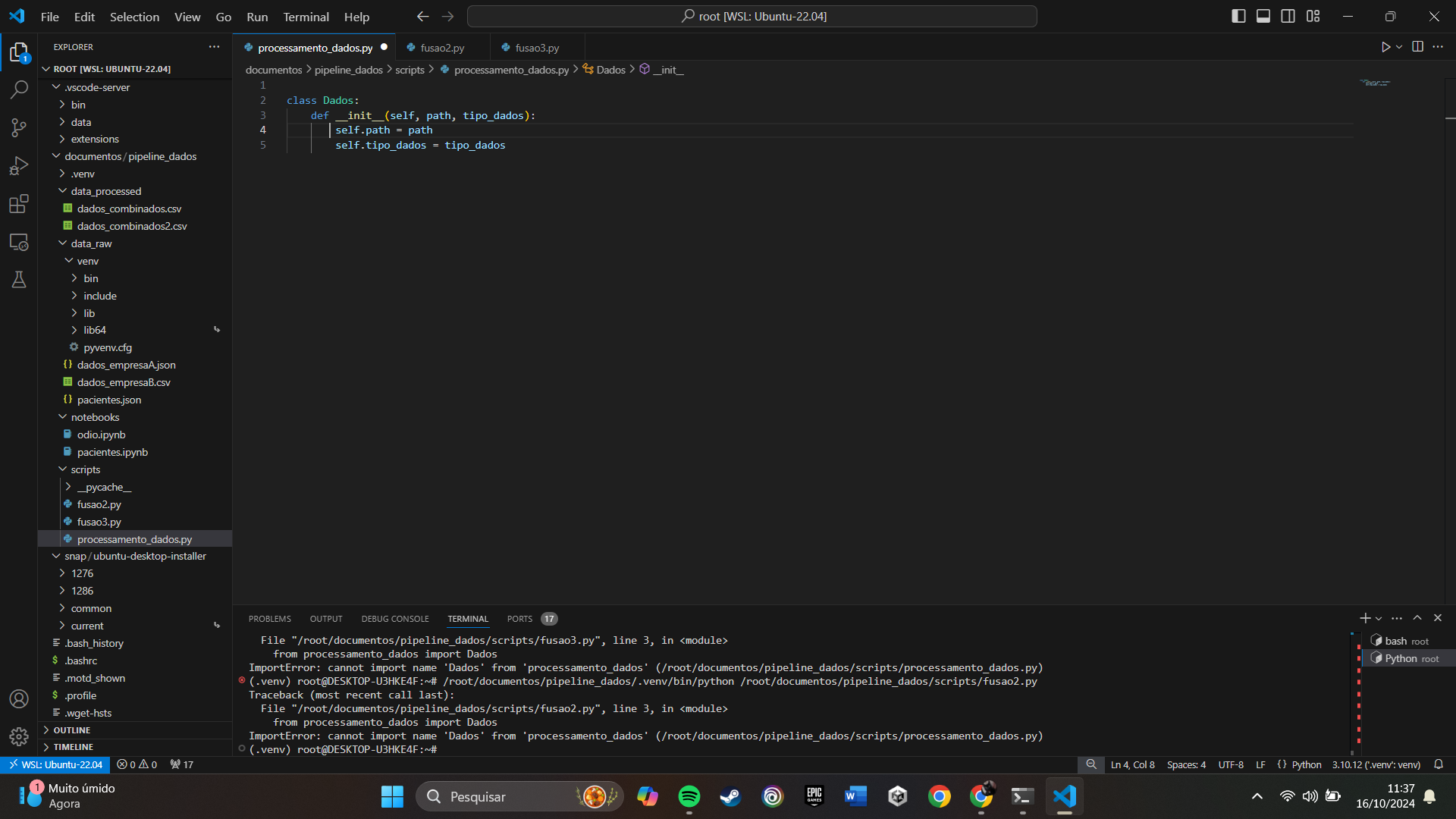
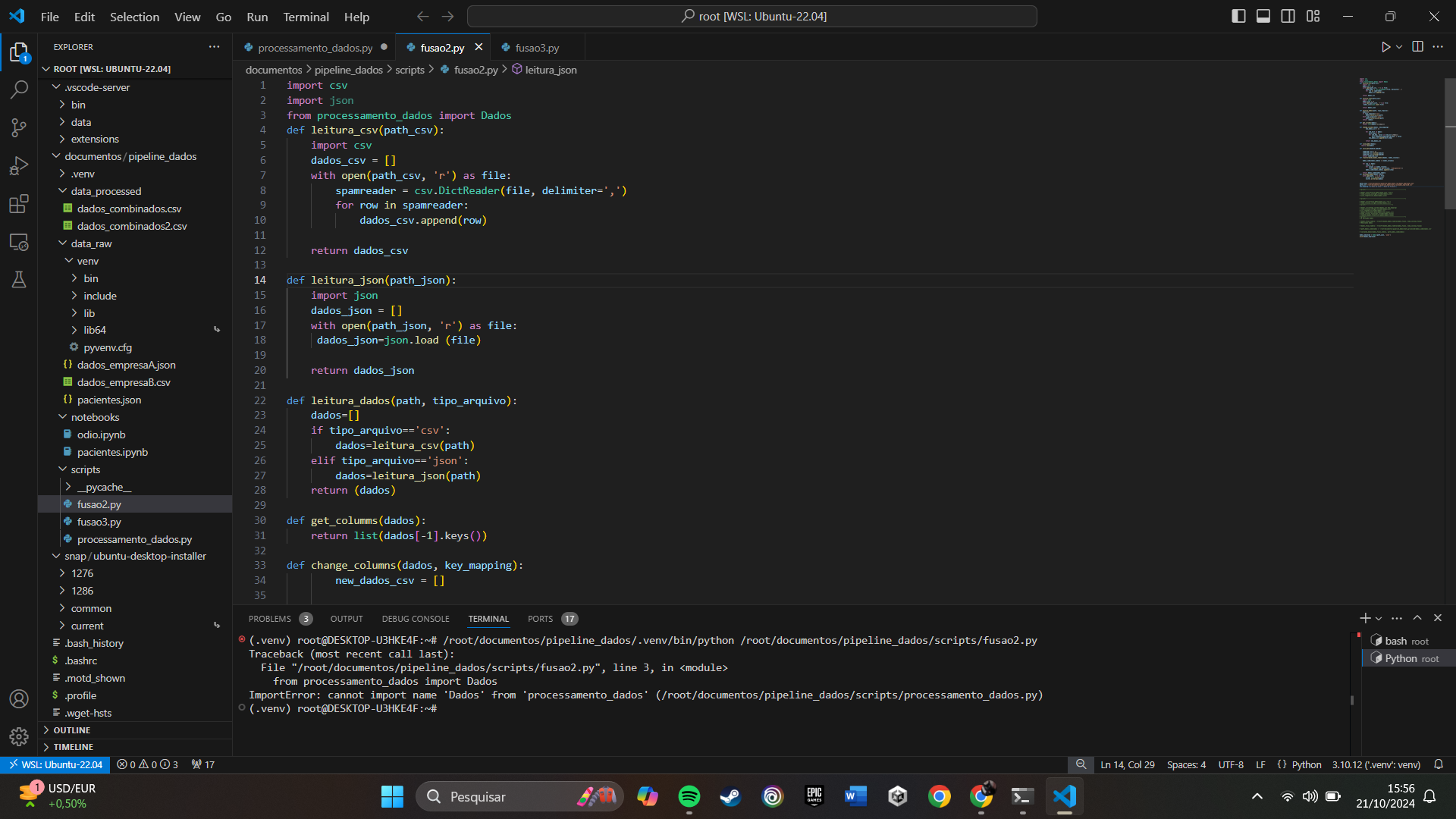
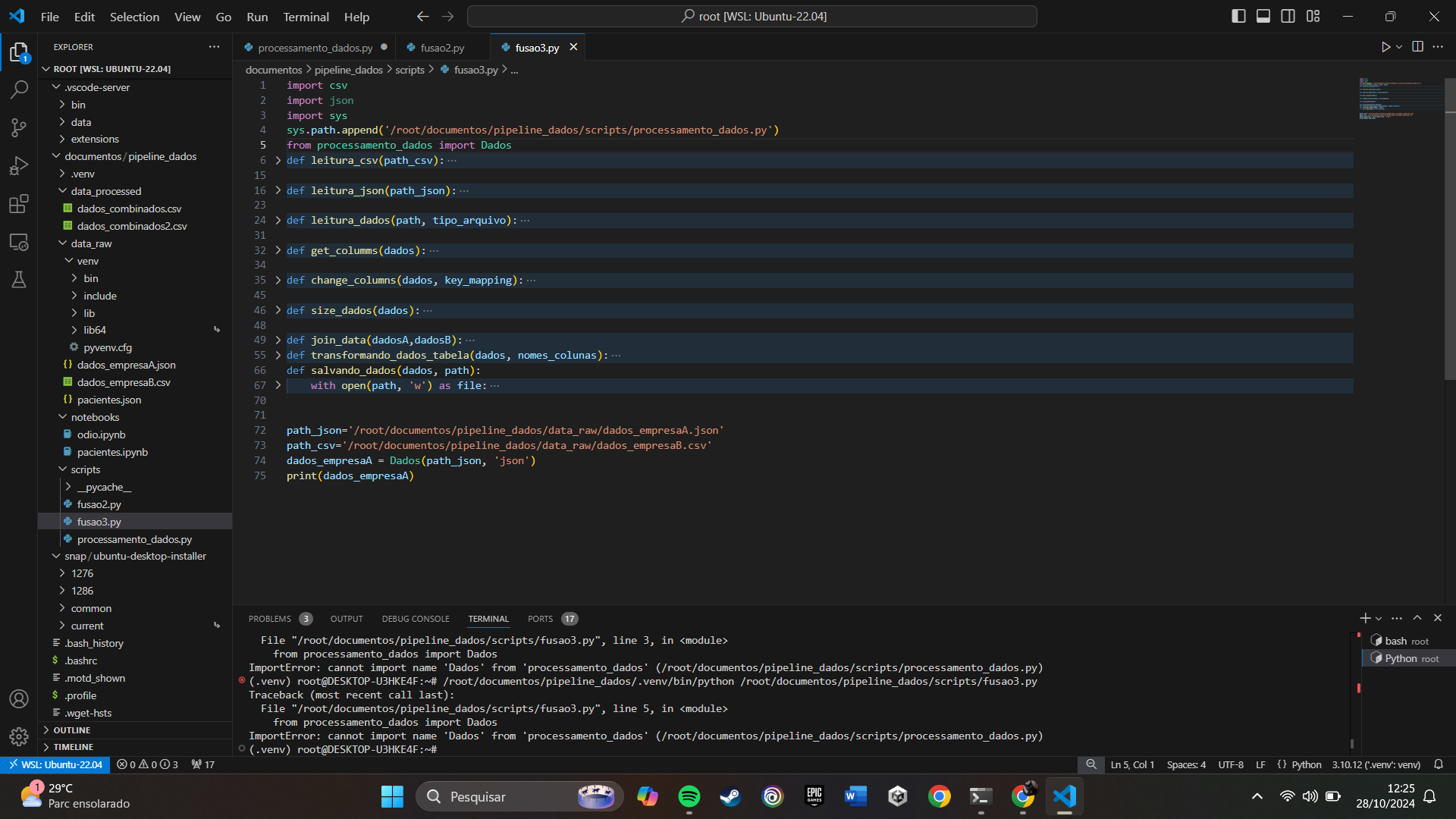
import csv
import json
from processamento_dados import Dados
def leitura_csv(path_csv):
import csv
dados_csv = []
with open(path_csv, 'r') as file:
spamreader = csv.DictReader(file, delimiter=',')
for row in spamreader:
dados_csv.append(row)
return dados_csv
def leitura_json(path_json):
import json
dados_json = []
with open(path_json, 'r') as file:
dados_json=json.load (file)
return dados_json
def leitura_dados(path, tipo_arquivo):
dados=[]
if tipo_arquivo=='csv':
dados=leitura_csv(path)
elif tipo_arquivo=='json':
dados=leitura_json(path)
return (dados)
def get_columms(dados):
return list(dados[-1].keys())
def change_columns(dados, key_mapping):
new_dados_csv = []
for old_dict in dados:
dict_temp = {}
for old_key, value in old_dict.items():
dict_temp[key_mapping[old_key]] = value
new_dados_csv.append(dict_temp)
return new_dados_csv
def size_dados(dados):
return len(dados)
def join_data(dadosA,dadosB):
combined_list = []
combined_list.extend(dadosA)
combined_list.extend(dadosB)
return combined_list
def transformando_dados_tabela(dados, nomes_colunas):
dados_combinados_tabela = [nomes_colunas]
for row in dados:
linha = []
for coluna in nomes_colunas:
linha.append(row.get(coluna, 'Indisponivel'))
dados_combinados_tabela.append(linha)
return dados_combinados_tabela
def salvando_dados(dados, path):
with open(path, 'w') as file:
writer =csv.writer(file)
writer.writerows(dados)
path_json='/root/documentos/pipeline_dados/data_raw/dados_empresaA.json'
path_csv='/root/documentos/pipeline_dados/data_raw/dados_empresaB.csv'
key_mapping = {'Nome do Item': 'Nome do Produto',
'Classificação do Produto': 'Categoria do Produto',
'Valor em Reais (R$)': 'Preço do Produto (R$)',
'Quantidade em Estoque': 'Quantidade em Estoque',
'Nome da Loja': 'Filial',
'Data da Venda': 'Data da Venda'}
# print("--------------------------------------------------")
# dados_json=leitura_dados(path_json,'json')
# nome_colunas_json=get_columms(dados_json)
# json_length=size_dados(dados_json)
# print("--------------------------------------------------")
# dados_csv=leitura_dados(path_csv,'csv')
# nome_colunas_csv=get_columms(dados_csv)
# print("---------------------------------")
# dados_csv=change_columns(dados_csv,key_mapping)
# nome_colunas_csv=get_columms(dados_csv)
# csv_length=size_dados(dados_csv)
# dados_fusao=join_data(dados_json,dados_csv)
# nome_colunas_fusao=get_columms(dados_fusao)
# tamanho_dados_fusao=size_dados(dados_fusao)
# print("--------------------------------------------------")
# # Salvando dados
# dados_fusao_tabela = transformando_dados_tabela(dados_fusao, nome_colunas_fusao)
# #Salvando dados
# dados_fusao_tabela = transformando_dados_tabela(dados_fusao, nome_colunas_fusao)
# path_dados_combinados = '/root/documentos/pipeline_dados/data_processed/dados_combinados.csv'
# salvando_dados(dados_fusao_tabela, path_dados_combinados)
dados_empresaA = Dados(path_json, 'json')
print(dados_empresaA)



{kind=link}