Oi
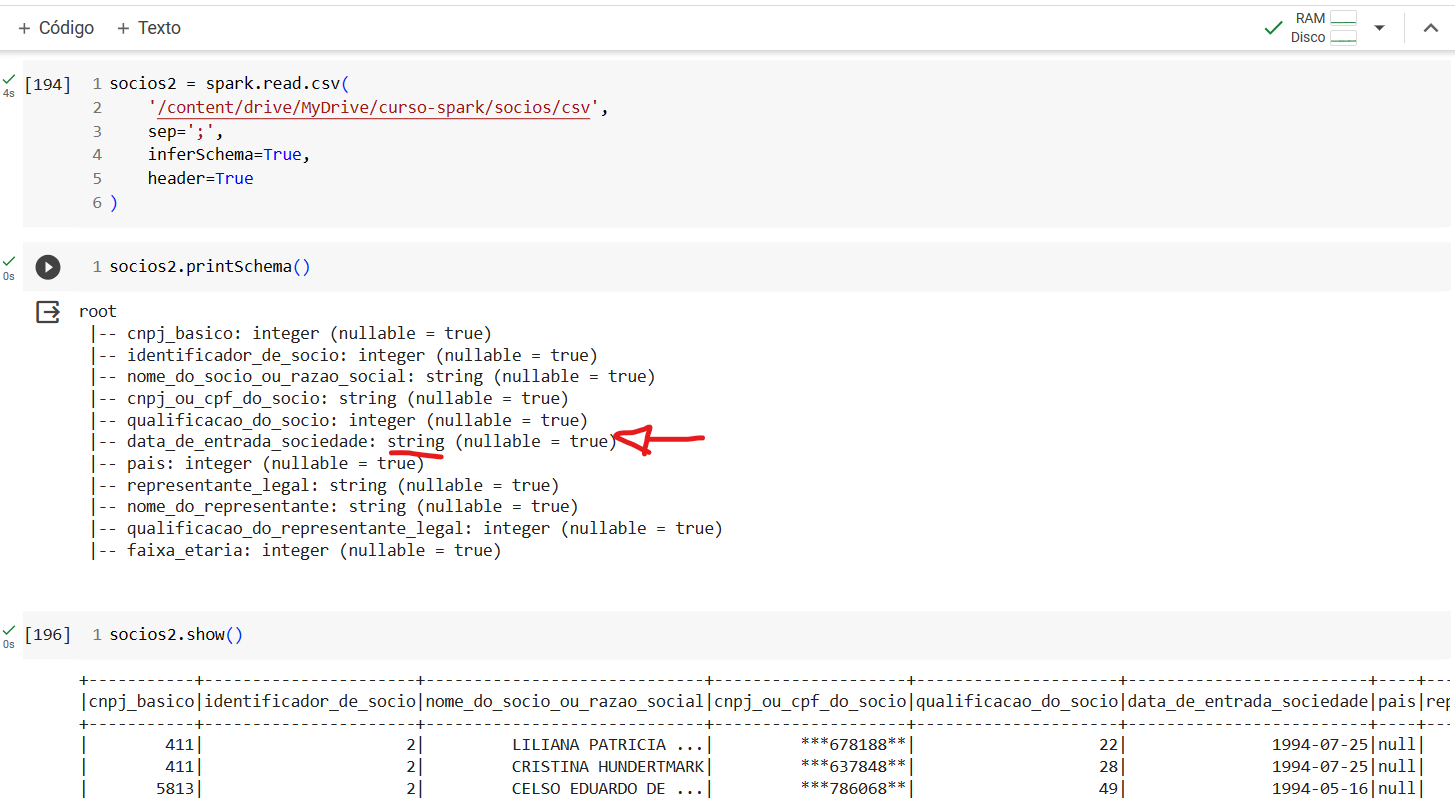
Primeiramente, é importante destacar que o comportamento que você observou, onde as datas anteriormente no formato "date" agora estão no formato "string," é uma consequência do processo de serialização e deserialização dos dados ao salvar e ler arquivos em CSV. Isso é um comportamento padrão e, em geral, não é específico do Spark, mas sim de como o CSV é tratado na maioria das bibliotecas de leitura e escrita de dados.
Quando você lê um arquivo CSV em qualquer linguagem de programação, incluindo o uso do Spark, os dados são lidos como texto (ou strings). Isso acontece porque o CSV é um formato de texto simples que não carrega informações sobre o tipo de dado das colunas. As datas, que eram originalmente do tipo "date" no seu DataFrame do Spark, são convertidas em strings ao serem salvas no arquivo CSV. Ao ler o arquivo CSV novamente, o Spark (ou outra biblioteca) interpreta essas datas como strings, a menos que você especifique explicitamente o tipo de dado durante a leitura.
Para resolver essa questão e manter as datas no formato "date" após a leitura do CSV, você precisa fazer uma conversão explícita durante a leitura dos dados. No Spark, você pode usar o método to_date para fazer essa conversão. Aqui está um exemplo:
from pyspark.sql.functions import to_date
from pyspark.sql.types import DateType
# Lê o arquivo CSV
df = spark.read.csv("seuarquivo.csv", header=True)
# Converte a coluna de data de string para date
df = df.withColumn("sua_coluna_data", to_date(df["sua_coluna_data"], "yyyy-MM-dd"))
# Agora a coluna de data está no formato DateType
No exemplo acima, to_date é usado para converter a coluna de data do formato string ("yyyy-MM-dd" é o formato esperado) para o formato "date" (DateType). Com isso, você preserva o tipo de dado correto.
É importante lembrar que ao salvar em CSV e depois ler os dados novamente, você está perdendo informações sobre os tipos de dados originais. Portanto, é fundamental fazer a conversão adequada no momento da leitura se você deseja manter a integridade dos tipos de dados.