
unit = dataset\
.groupBy("customerID")\
.pivot('unit')\
.agg(f.lit(1))\
.na\
.fill(0)zone = dataset\
.groupBy('customerID')\
.pivot('zone')\
.agg(f.lit(1))\
.na\
.fill(0)Quando não uso, no final destes métodos o método ".show()", eles rodam normalmente. Mas, quando coloco o método .show() no final destes dois datasets, dá erro. Porque?
exemplo:
unit = dataset\
.groupBy("customerID")\
.pivot('unit')\
.agg(f.lit(1))\
.na\
.fill(0)\
.show()ao rodar o código abaixo:
dataset = dataset\
.join(unit, 'customerID', how='inner')\
.join(zone, 'customerID', how='inner')Veja o erro abaixo:
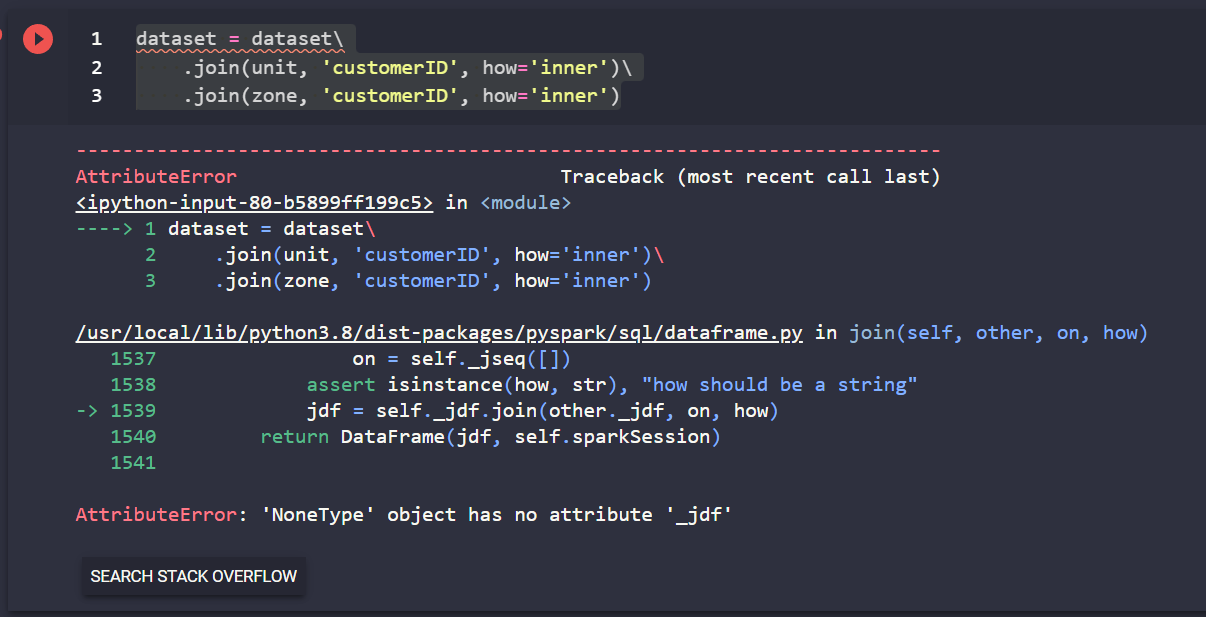
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-80-b5899ff199c5> in <module>
----> 1 dataset = dataset\
2 .join(unit, 'customerID', how='inner')\
3 .join(zone, 'customerID', how='inner')
/usr/local/lib/python3.8/dist-packages/pyspark/sql/dataframe.py in join(self, other, on, how)
1537 on = self._jseq([])
1538 assert isinstance(how, str), "how should be a string"
-> 1539 jdf = self._jdf.join(other._jdf, on, how)
1540 return DataFrame(jdf, self.sparkSession)
1541
