Olá, boa tarde Luiz! Espero que esteja bem.
Estou utilizando alguns dados "improvisados", diferente dos seus. Entretanto, a explicação será a mesma para ambos os casos.
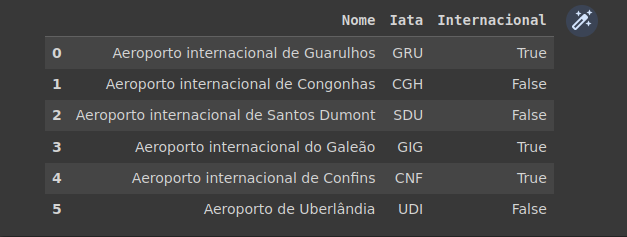
Primeiramente, lhe apresento os dados que estou utilizando e o retorno:
import pandas as pd
aeroportos_saopaulo = [
{'Nome':'Aeroporto internacional de Guarulhos','Iata':'GRU','Internacional':True},
{'Nome':'Aeroporto internacional de Congonhas','Iata':'CGH','Internacional':False}
]
aeroportos_riodejaneiro = [
{'Nome':'Aeroporto internacional de Santos Dumont','Iata':'SDU','Internacional':False},
{'Nome':'Aeroporto internacional do Galeão','Iata':'GIG','Internacional':True}
]
aeroportos_minasgerais = [
{'Nome':'Aeroporto internacional de Confins','Iata':'CNF','Internacional':True},
{'Nome':'Aeroporto de Uberlândia','Iata':'UDI','Internacional':False}
]
dataset_saopaulo = pd.DataFrame(aeroportos_saopaulo)
dataset_riodejaneiro = pd.DataFrame(aeroportos_riodejaneiro)
dataset_minasgerais = pd.DataFrame(aeroportos_minasgerais)
dataset_sudeste = pd.merge(dataset_saopaulo,dataset_riodejaneiro,
how='outer')
dataset_sudeste = pd.merge(dataset_sudeste,dataset_minasgerais,
how='outer')
dataset_sudeste
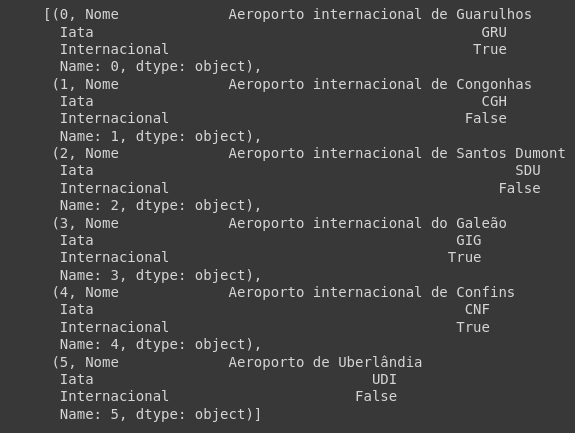
Agora, utilizando o método iterrows sozinho, vejamos o retorno:
# Vejamos o retorno de iterrows sozinho
list(dataset_sudeste.iterrows())
# Analisando este retorno, podemos ver que ele retorna na lista dois itens.
# O primeiro deles é o item index, marcado de 0 à 4 no meu caso.
# O segundo, são, o que podemos chamar de chaves e valores do DataFrame.
# Mas, como o Python sabe quais são index, e quais são as chaves e valores?
# Simples, durante a execução do método, o próprio iterrows realiza a criação das series para cada linha.
# O iterrows esta funcionando como uma espécie alternativa de método zip, entretanto gerando series para cada linha.
# No meu caso, esta serie vai de 0 à 5.
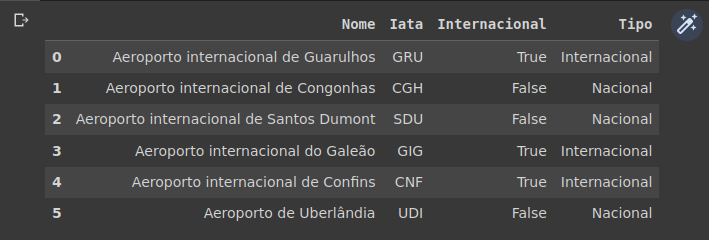
Agora, vejamos o retorno no laço for:
# Neste laço for desejo encontrar os aeroportos que não são internacionais.
# Caso aeroporto não seja internacional, irei tipar como nacional (vice e versa).
for index, row in dataset_sudeste.iterrows():
# Avaliando se o aeroporto é internacional.
# Isto funciona parecido com o dicionario.
# name_dict[key] return value
if row['Internacional'] == False:
dataset_sudeste.loc[index,'Tipo'] = 'Nacional'
# Caso nao atenda a condição anterior
else:
dataset_sudeste.loc[index,'Tipo'] = 'Internacional'
dataset_sudeste
# Como vimos o loc, utiliza do index, para marcar a linha, e atribuir o valor.
# O nome 'Tipo' simplesmente, cria a nova coluna.
Espero que tenha conseguido lhe ajudar.
Excelente estudos ">



