
Boa tarde!
Na aula sobre vetorização dos tokens de NLP com o objeto CountVectorizer foi mostrado que era possível identificar as palavras presentes no modelo com o auxílio do método "vocabulary", tal como no print a seguir:
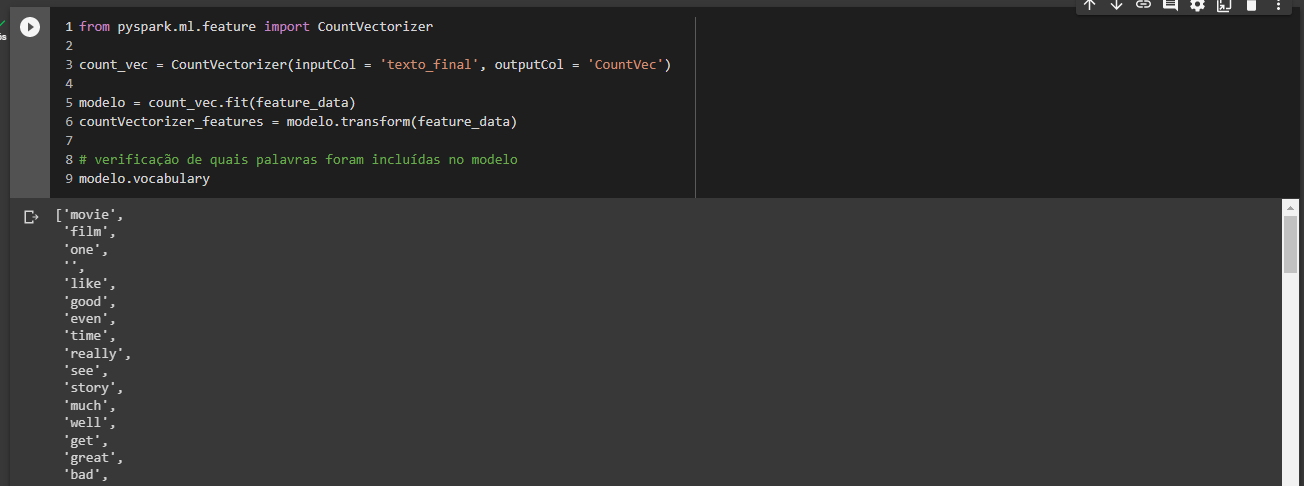 Nessa aula vimos que é possível construir a mesma vetorização utilizando o objeto HashingTF, também do PySpark, com a vantagem de que esse último é mais simples de ser aplicado ao dataset (não exige a definição de um modelo). Mas existe algum análogo do "vocabulary" para o HashingTF? Em outras palavras, sabemos que podemos escolher quantos tokens nosso conjunto de dados terá, mas podemos consultar quais foram escolhidos pelo algoritmo?
Nessa aula vimos que é possível construir a mesma vetorização utilizando o objeto HashingTF, também do PySpark, com a vantagem de que esse último é mais simples de ser aplicado ao dataset (não exige a definição de um modelo). Mas existe algum análogo do "vocabulary" para o HashingTF? Em outras palavras, sabemos que podemos escolher quantos tokens nosso conjunto de dados terá, mas podemos consultar quais foram escolhidos pelo algoritmo?
Desde já, agradeço a atenção!

