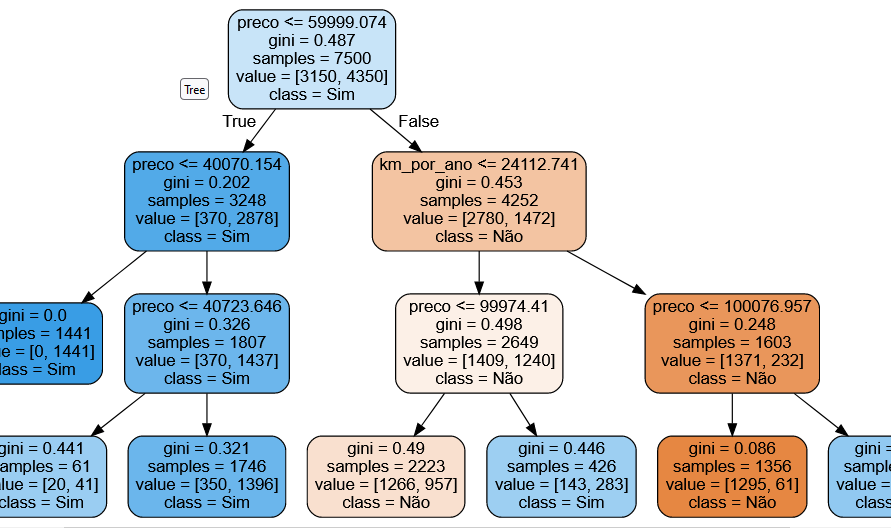
Bom dia. Quanto maior a complexidade da árvore maiores são as chances dela interpretar pequenos valores "falsos" mas dentro de certas características plausíveis de serem classificadas como "Sim", que no caso é o vendido.
Não é pelo fato de você ter separado em uma nova folha de decisão que o modelo deve pegar aqueles valores e dar um resultado "Sim" e "Não". O que ele está fazendo é interpretando um conjunto de dados e avaliando dentro dele os que podem ser vendidos e não, se em sua maioria pode ser vendido então ele pega esse conjunto e diz que pode ser vendido, mesmo tendo outros dados dentro que não deveriam ser vendidos.
É como se eu pegasse um saco de bolas coloridas e olhando por cima visse que havia mais bolas vermelhas que verde, daí alguém me pergunta, "as bolas são vermelhas?", e eu respondo "Sim!". Daí eu pego esse mesmo saco e separo em dois outros, S1 e S2, e a pessoa faz a mesma pergunta, e por algum motivo a divisão continua nos 2 sacos mais vermelhas, e minha resposta continua "sim" para os 2 sacos, ou seja True e True para ambos, mesmo sabendo que há verdes. Então uma nova divisão para cada saco, etc., em algum momento pode haver verdes em quantidades maiores que as vermelhas e haverá uma resposta "false", mas mesmo que fosse o contrário, se fossem mais Falses em algum momento poderia ter um "True". Neste caso o importante é a maneira como você divide o conjunto de amostragem.
Por isso uma melhor classificação é dada com muitas separações, porém pode ter o overfit ou divergir do resultado real, sendo o controle dos hiperparâmetros extremamente importante.
Espero ter ajudado.