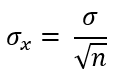Por quê as funções zconfint e norm.interval não geraram o mesmo resultado para o intervalo de confiança abaixo?
import pandas as pd
import numpy as np
from scipy.stats import norm
from statsmodels.stats.weightstats import zconfint
np.random.seed(0) ## Gera sempre o mesmo número aleatório
populacao = pd.Series(np.random.randint(2000, size=(800)))
desvio_padrao_populacional = populacao.std()
amostra = populacao.sample(n=400)
n_amostra = amostra.shape[0]
sigma_x = desvio_padrao_populacional/n_amostra
media_amostra = amostra.mean()
significancia = 0.05
confianca = 0.95
norm.interval(alpha=0.95,loc=media_amostra,scale=sigma_x)(998.7867458833483, 1004.3582541166517)
zconfint(amostra)(945.6874888730528, 1057.457511126947)