Para explicar essa situação de forma simples e sem muitos termos técnicos, vou usar uma analogia e focar no conceito de "erro" ou "distância" entre os pontos e a reta de regressão.
Explicação simples:
O que é a reta de regressão?
A reta de regressão é uma linha que tenta "prever" ou "resumir" o comportamento dos dados. Ela é desenhada de forma a ficar o mais perto possível de todos os pontos no gráfico.
O que a função linalg.norm mede?
A função linalg.norm mede o "erro total" entre os pontos reais e a reta de regressão. Quanto menor esse valor, mais próximos os pontos estão da reta. É como se fosse uma medida de "quanto os pontos estão fora do lugar".
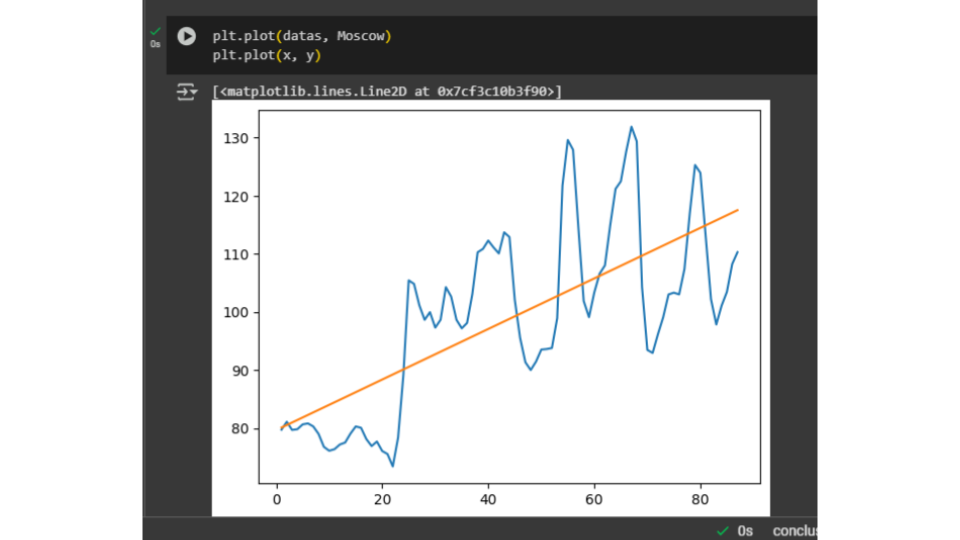
Por que o gráfico de Moscow tem um linalg.norm menor, mas parece menos alinhado?
Imagine que os preços das maçãs em Moscow variam muito (os pontos estão espalhados), mas a reta de regressão foi desenhada de forma que os erros (as distâncias dos pontos até a reta) são pequenos em média. Isso pode acontecer se os pontos estiverem relativamente próximos da reta, mas em grandes quantidades.
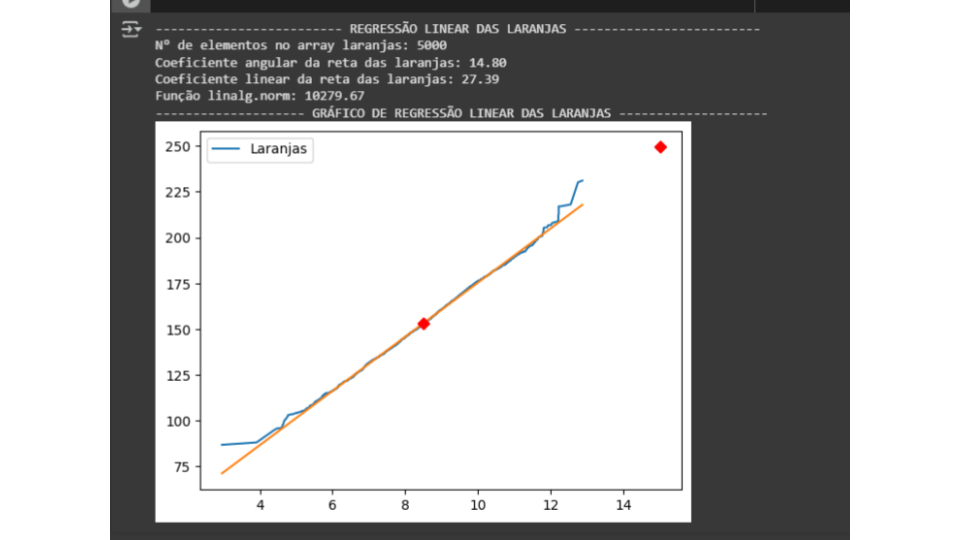
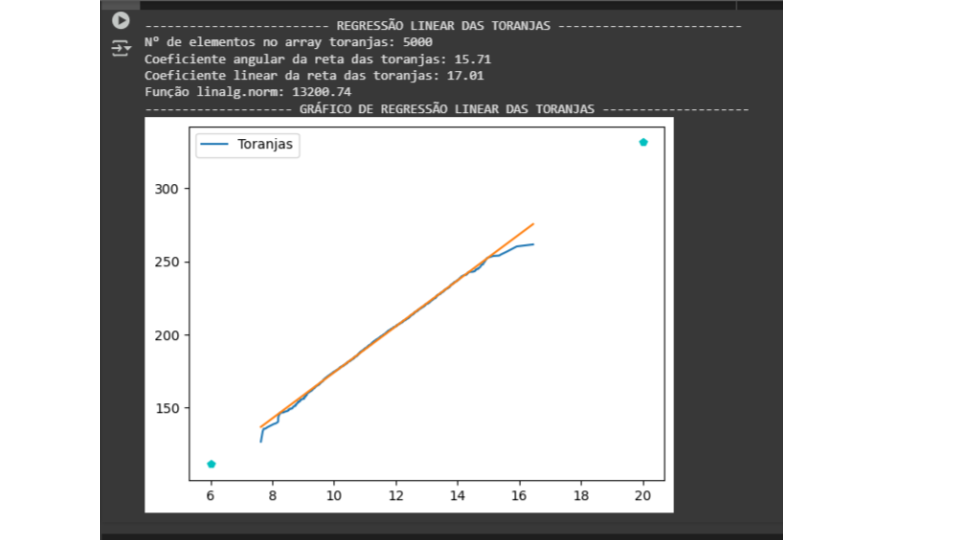
Já no caso das laranjas e toranjas, os pontos podem estar mais alinhados visualmente, mas alguns pontos estão muito longe da reta. Esses pontos "fora do padrão" aumentam muito o valor do linalg.norm, mesmo que a maioria dos pontos esteja bem alinhada.
Resumindo:
O linalg.norm mede o erro total, não apenas o alinhamento visual. No caso de Moscow, os erros são pequenos, mas os pontos estão mais espalhados. Já nas laranjas e toranjas, alguns pontos estão muito longe da reta, o que aumenta o erro total, mesmo que a maioria dos pontos esteja bem alinhada.
Analogia:
Pense em duas turmas de alunos:
Na turma de Moscow, todos os alunos tiraram notas parecidas (erros pequenos), mas essas notas variam bastante (pontos espalhados).
Na turma das laranjas e toranjas, a maioria dos alunos tirou notas muito parecidas (pontos alinhados), mas alguns alunos tiraram notas muito diferentes (pontos distantes), o que "estraga" a média.
O linalg.norm é como a soma de todas as diferenças das notas em relação à média. Na turma de Moscow, as diferenças são pequenas, mas há muitas. Nas outras turmas, as diferenças são grandes para alguns alunos, o que aumenta o valor total.
Espero que isso ajudado .