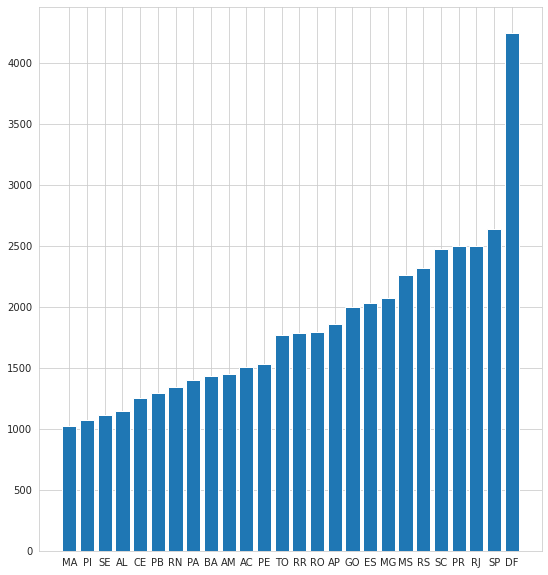
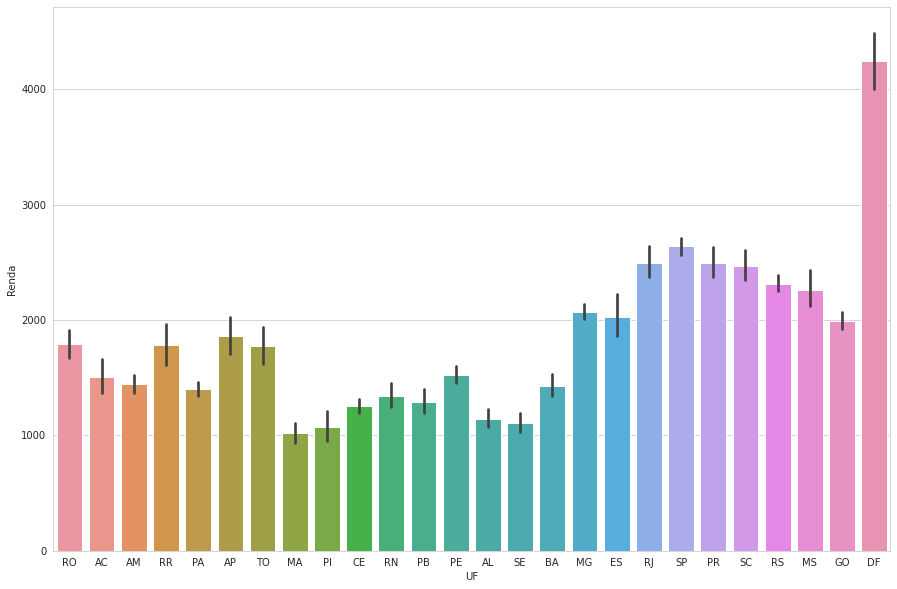
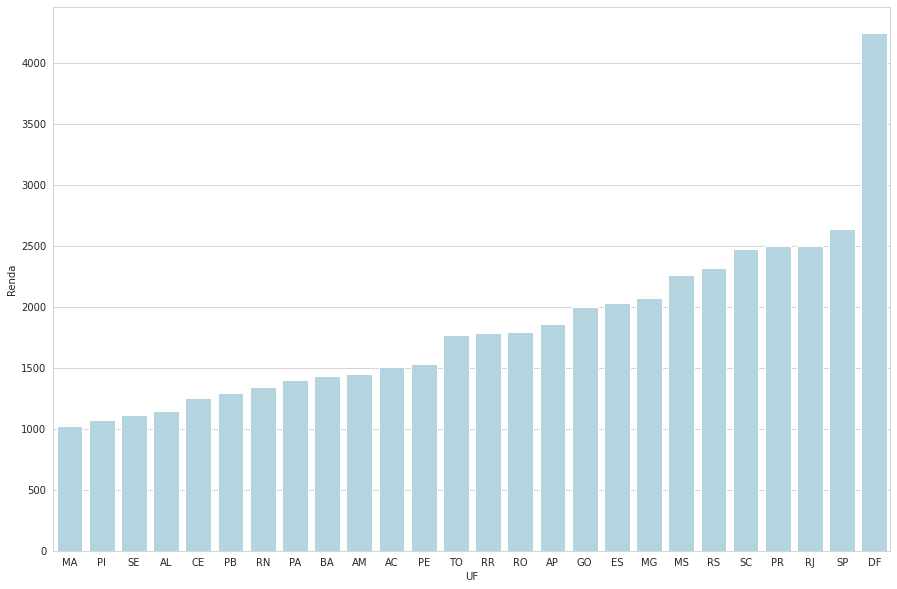
Eu fiz uma média de valores para cada UF:
# A renda está concentrada em quais estados?
# Fazendo uma series;
media_renda_por_uf = dados.groupby('UF')['Renda'].mean().sort_values()
media_renda_por_ufdados é o DataFrame diretamente do csv da atividade. Devolveu:
UF
MA 1019.432009
PI 1074.550784
SE 1109.111111
AL 1144.552602
CE 1255.403692
PB 1293.370487
RN 1344.721480
PA 1399.076871
BA 1429.645094
AM 1445.130100
AC 1506.091782
PE 1527.079319
TO 1771.094946
RR 1783.588889
RO 1789.761223
AP 1861.353516
GO 1994.580794
ES 2026.383852
MG 2070.515707
MS 2262.604167
RS 2315.158336
SC 2470.854945
PR 2493.870753
RJ 2496.403168
SP 2638.104986
DF 4241.954722
Name: Renda, dtype: float64Porém, estou com muita dificuldade em usar essa Series para fazer o histograma com seus valores. Como posso fazer? Resultou errado quando:
renda_por_uf = sns.displot(data = media_renda_por_uf,
x = media_renda_por_uf.keys(),
y = media_renda_por_uf,
kind='hist').figure.set_size_inches(10,8)
renda_por_uf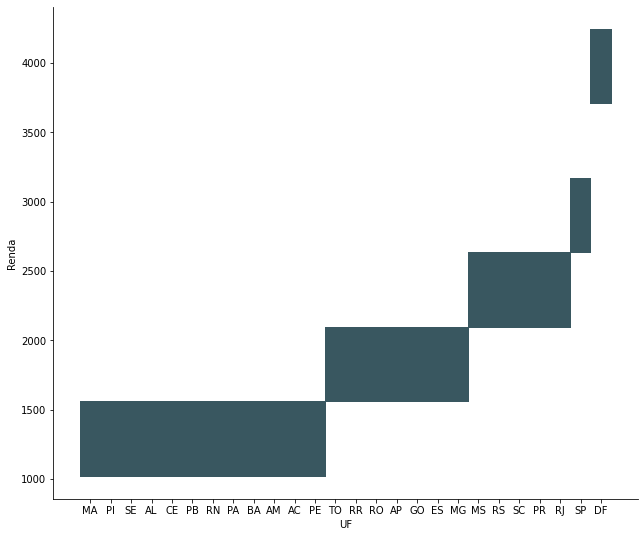 O gráfico ficou todo errado. Quero uma coluna única para cada UF, mas há cinco colunas aglomeradas por algum motivo estranho.
O gráfico ficou todo errado. Quero uma coluna única para cada UF, mas há cinco colunas aglomeradas por algum motivo estranho.
Por enquanto, consegui criar esse gráfico, mas ainda não é o que eu desejo, pois não exibe uma média:
renda_por_uf = sns.displot(data = dados,
x = dados.UF.sort_values(),
y = dados.Renda,
color = 'r',
kind='hist').figure.set_size_inches(10,8)
renda_por_uf