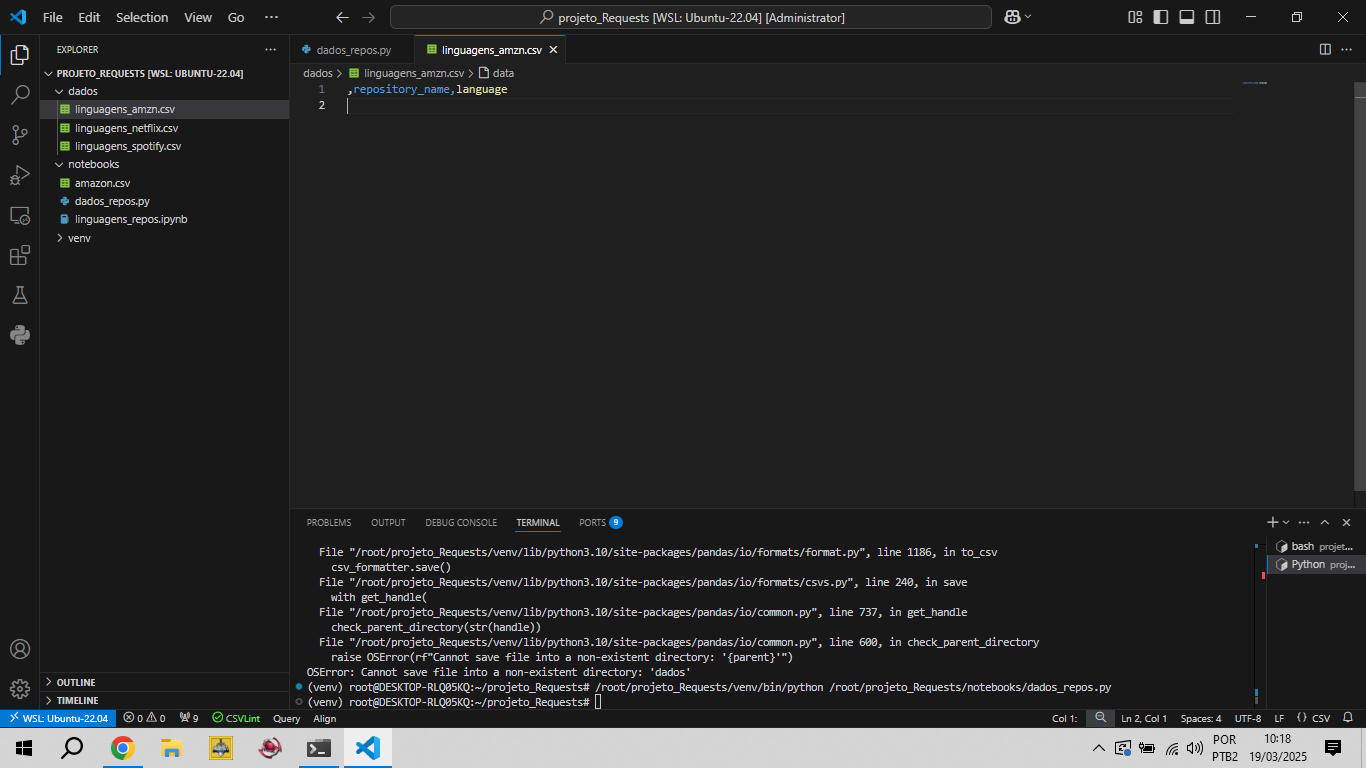
Bom dia, venho tentando realizar esse projeto porem meu data frame só da como vazio. Também tive duvidas em outras partes ao qual perguntei no discord e não houve respostas...
import requests
import pandas as pd
class DadosRepositorios:
def __init__(self, owner):
self.owner = owner
self.api_base_url = 'https://api.github.com'
self.access_token='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'
self.headers = {'Authorization': 'Bearer ' + self.access_token,
'X-GitHub-Api-Version': '2022-11-28'}
def lista_repositorios (self):
repos_list = []
for page_num in range(1, 20):
try:
url = f'{self.api_base_url}/users/{self.owner}/repos?page={page_num}'
response = requests.get(url, headers=self.headers)
repos_list.append(response.json())
except:
repos_list.append(None)
return repos_list
def nomes_repos(self, repos_list):
repo_names=[]
for page in repos_list:
for repo in page:
try:
repo_names.append(repo['name'])
except:
pass
return repo_names
def nomes_linguagens(self, repos_list):
repo_languages=[]
for page in repos_list:
for repo in page:
try:
repo_languages.append(repo['language'])
except:
pass
return repo_languages
def cria_df_linguagens (self):
repositorios = self.lista_repositorios()
nomes = self.nomes_repos (repositorios)
linguagens = self.nomes_linguagens (repositorios)
dados = pd.DataFrame()
dados['repository_name'] = nomes
dados['language'] = linguagens
return dados
amazon_rep = DadosRepositorios('amzn')
ling_mais_usadas_amzn = amazon_rep.cria_df_linguagens()
netflix_rep = DadosRepositorios('netflix')
ling_mais_usadas_netflix = netflix_rep.cria_df_linguagens()
spotify_rep = DadosRepositorios('spotify')
ling_mais_usadas_spotify = spotify_rep.cria_df_linguagens()
# Salvando os dados
ling_mais_usadas_amzn.to_csv('dados/linguagens_amzn.csv')
ling_mais_usadas_netflix.to_csv('dados/linguagens_netflix.csv')
ling_mais_usadas_spotify.to_csv('dados/linguagens_spotify.csv')