
Na aula anterior eu executei o código e ele funcionou. Consegui criar a pasta "datalake" com o arquivo segundo a data de hoje. Em seguida realizei as alterações para criar a tabela, a partição e o arquivo dentro do datalake, no entanto estou obtendo o erro de DagRun not found. Segue print do erro:
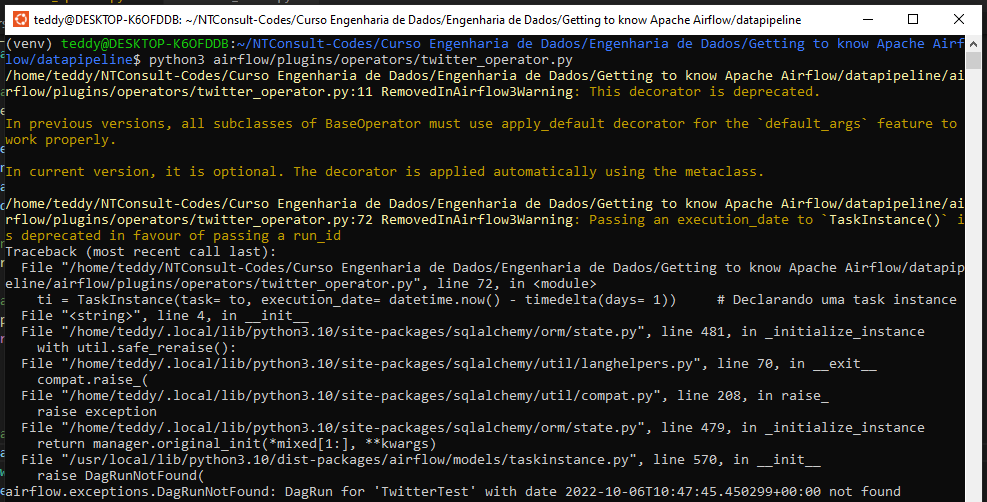
Segue o código com as alterações realizadas para colocar a tabela e partições dentro do datalake:
import sys
sys.path.append("/home/teddy/NTConsult-Codes/Curso Engenharia de Dados/Engenharia de Dados/Getting to know Apache Airflow/datapipeline/airflow/plugins")
from airflow.models import BaseOperator, DAG, TaskInstance
from airflow.utils.decorators import apply_defaults
from hooks.twitter_hook import TwitterHook
import json
from datetime import datetime, timedelta
from pathlib import Path
from os.path import join
class TwitterOperator(BaseOperator):
template_fields = [
"query",
"file_path",
"start_time",
"end_time"
]
# Aplicando os defaults
@apply_defaults
# query, conn_id, start_time e end_time sao informacoes que vem do gancho e serão utilizadas aqui pelo operador
def __init__(
self,
query,
file_path,
conn_id = None,
start_time= None,
end_time = None,
*args, **kwargs
):
super().__init__(*args, **kwargs) # Inicializando a classe pai
self.query = query # Recebendo os valores recebidos na iniciação da classe
self.file_path = file_path
self.conn_id = conn_id
self.start_time = start_time
self.end_time = end_time
def create_parent_folder(self):
Path(Path(self.file_path).parent).mkdir(parents= True, exist_ok= True)
# Função para executar o hook por meio do operador
def execute(self, context):
hook = TwitterHook(
query = self.query,
conn_id = self.conn_id,
start_time = self.start_time,
end_time = self.end_time
)
# Criando a pasta para conter o arquivo
self.create_parent_folder()
# Ainda dentro da função, fazemos o for para poder imprimir o retorno da função run() do hook!!!
with open(self.file_path, 'w') as output_file:
for pg in hook.run():
json.dump(pg, output_file, ensure_ascii= False)
output_file.write('\n')
if __name__ == '__main__':
# Instânciando uma DAG para fazer uso do operador.
with DAG(dag_id='TwitterTest',start_date= datetime.now()) as dag:
to = TwitterOperator(
query= 'AluraOnline',
# Acrescentando o caminho enteiro para criar uma pasta e criar o nosso "data lake"
file_path= join(
"/home/teddy/NTConsult-Codes/Curso Engenharia de Dados/Engenharia de Dados/Getting to know Apache Airflow/datapipeline/datalake", # Criando diretorio
"twitter_aluraonline", # Tabela dentro do nosso "data lake"
"extract_date={{ ds }}", # Partição dentro da tabela com a data de extração
"AluraOnline_{{ ds_nodash}}.json"),
task_id='test_run') # Declarando o operador propriamente dito
ti = TaskInstance(task= to, execution_date= datetime.now() - timedelta(days= 1)) # Declarando uma task instance
to.run()
#to.execute(ti.task_id) # Finalmente executando o operador com o id da task.Estou fazendo to.run(), pois na aula anterior foi assim como eu consegui fazer ele executar corretamente.
Estou utilizando airflow versão 2.4.1
