Percebi que quanto maiores são meus arquivos, mais tokens o assistente usa dentro da thread. Ou seja, para cada mensagem enviada, eu pago todos os tokens dos arquivos ?
Pelo pricing da openai, o retrieval cobraria por arquivo e não por token.
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Percebi que quanto maiores são meus arquivos, mais tokens o assistente usa dentro da thread. Ou seja, para cada mensagem enviada, eu pago todos os tokens dos arquivos ?
Pelo pricing da openai, o retrieval cobraria por arquivo e não por token.


Oi, Caio, tudo bem?
Apenas é cobrado os tokens gerados nas mensagens enviadas para o assistente, não pelos tokens contidos nos arquivos em si. Se você envia um arquivo para o assistente e ele gera uma resposta com base nesse arquivo, você paga pelos tokens gerados na resposta, não pelos tokens no arquivo.
Por exemplo, se você envia um arquivo de 1 MB para o assistente e ele responde com uma mensagem de 100 tokens, você paga apenas pelos 100 tokens da resposta, não pelos tokens contidos no arquivo. O tamanho do arquivo em si não afeta diretamente o custo, apenas a quantidade de tokens gerados nas respostas do assistente.
Espero ter ajudado. Caso tenha dúvidas, conte com o fórum. Abraços!
Olá Rodrigo, obrigado pela resposta.
Eu tenho alguns testes que venho aplicando, usando os complete's com e sem o retrieval, e sempre que uso o retrieval, aquantiade dos tokens cobrados são sensivelmente maior.
Isso é possível ver pelo próprio playground. Veja na imagem abaixo:
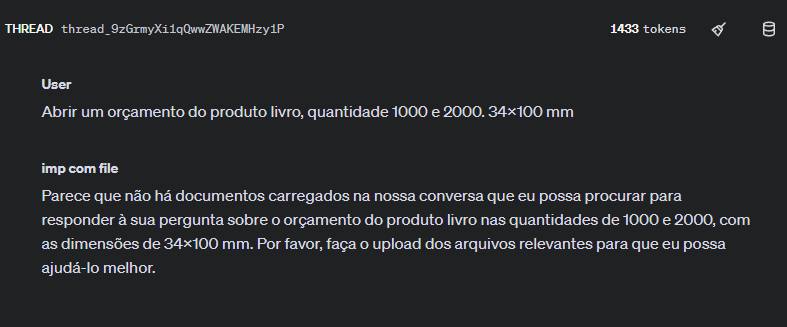
O texto do Role "User", do Role "Assistent" e da resposta, não tem mais do que 200 tokens.
Veja na ferramenta Tokenizer:
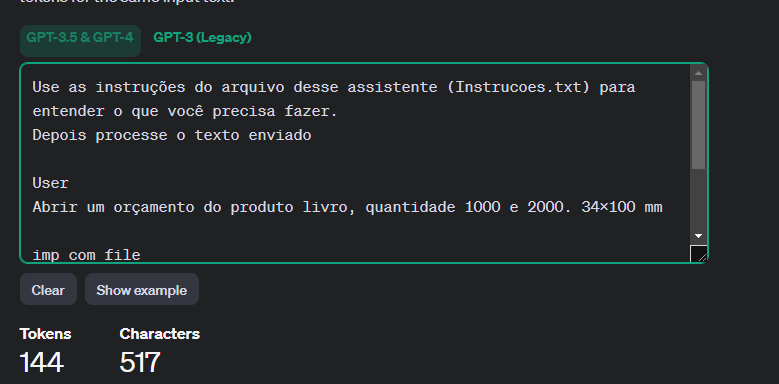
Não ficou claro para mim o motivo de ter contabilizado 1433 tokens como apresentado na figura 1.
Oi, Caio, tudo bem?
Quando você utiliza o retrieval, o assistente tem acesso a uma quantidade maior de informações para gerar uma resposta, o que pode resultar em respostas mais detalhadas e, portanto, em um uso maior de tokens. Mesmo que o texto enviado e a resposta direta do assistente sejam curtos, o assistente pode ter consultado várias fontes durante o processo de geração da resposta, o que contribui para o aumento na contagem de tokens.
Vou encaminhar um link sobre essa contagem de tópicos usando o retrieval, dentro da própria comunidade da Open AI.
Espero que dê tudo certo. Abraços!