
Olá.
Tenho uma dúvida à respeito do funcionamento do cross validate.
Lendo a documentação sobre cross validation do Sklearn (https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation), ela explica que inicialmente uma parte do dataset é resguardada para teste e que os dados de treino são splitados em k folds e feita a validação uma a uma. A própria figura ilustrativa indica isto:
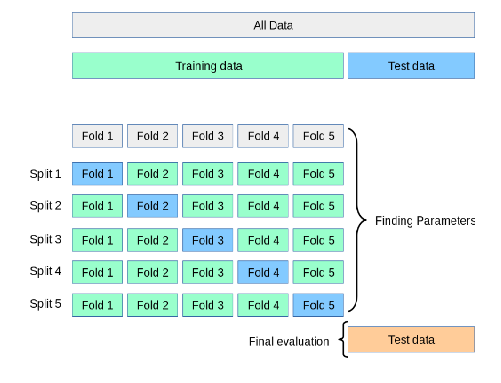
Ou seja, após a validação cruzada, teríamos uma avaliação final com os dados de teste preservados.
No entanto, durante o curso utilizou-se o dataset inteiro para a função cross validate (a bem da verdade, na própria documentação do sklearn se utiliza no exemplo após a imagem o dataset Iris inteiro).
Não teríamos um enviesamento do modelo ao não separar uma parte inicialmente?
Obrigado.


