
Esse artigo aqui da Alura cita o backpropagation e explica um pouco sobre ele. Porém tenho algumas duvidas. https://www.alura.com.br/artigos/desmistificando-termos-machine-learning
O artigo cita o seguinte: "o backpropagation, ou em português retropropagação, que funciona em duas etapas: para frente (forward) e para trás (backward). [...] Em outras palavras, ele utiliza o cálculo de gradiente descendente de forma automatizada, fazendo com que o algoritmo caminhe para frente e para trás pelas camadas intermediárias, buscando diminuir a taxa de erro até convergir a melhor solução, ou seja, a melhor acurácia."
Porém, eu queria me aprofundar mais sobre como o backpropagation funciona. Queria entender mais a fundo as etapas que ele segue, pra entender os calculos que estão envolvidos, e em qual ordem as etapas são feitas.
Eu ja pesquisei um pouco sobre isso na internet. Porém ja me deparei com fórmulas matriciais que usam matrizes, e eu acho essas fórmulas complicadas de entender. Então por isso quis perguntar sobre o backpropagation aqui.
Por favor, algúem poderia me explicar em mais detalhes o que acontece em cada uma dessas etapas?
Gostaria de fazer algumas perguntas sobre o backpropagation:
1 - Quais etapas o backpropagation utiliza?
2 - Qual a ordem que essas etapas são realizadas? o que vem primeiro, o que vem depois?
3 - Nessas etapas quais fórmulas matematicas são utilizadas?
4 - De que maneira o algoritmo caminha "para frente e para trás pelas camadas intermediárias" ?
Eu gostaria de conseguir executar esses calculos na mão, no papel e caneta, pra aprender mais sobre o backpropagation. Por favor, algúem poderia me explicar mais sobre o assunto?



 Fiquei com essa duvida: Pelo que indica esse indice K parecem ser camadas, então, logo K+1 parece ser a camada seguinte. Mais não tenho certeza se entendi certo.. Nessa outra imagem abaixo destaquei algumas coisas que fiquei com um pouco de duvida.
Fiquei com essa duvida: Pelo que indica esse indice K parecem ser camadas, então, logo K+1 parece ser a camada seguinte. Mais não tenho certeza se entendi certo.. Nessa outra imagem abaixo destaquei algumas coisas que fiquei com um pouco de duvida.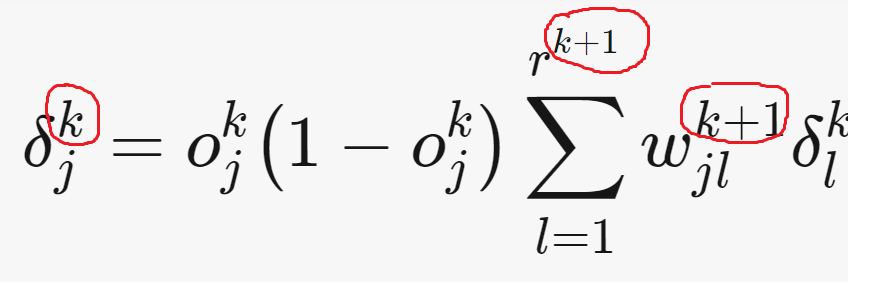
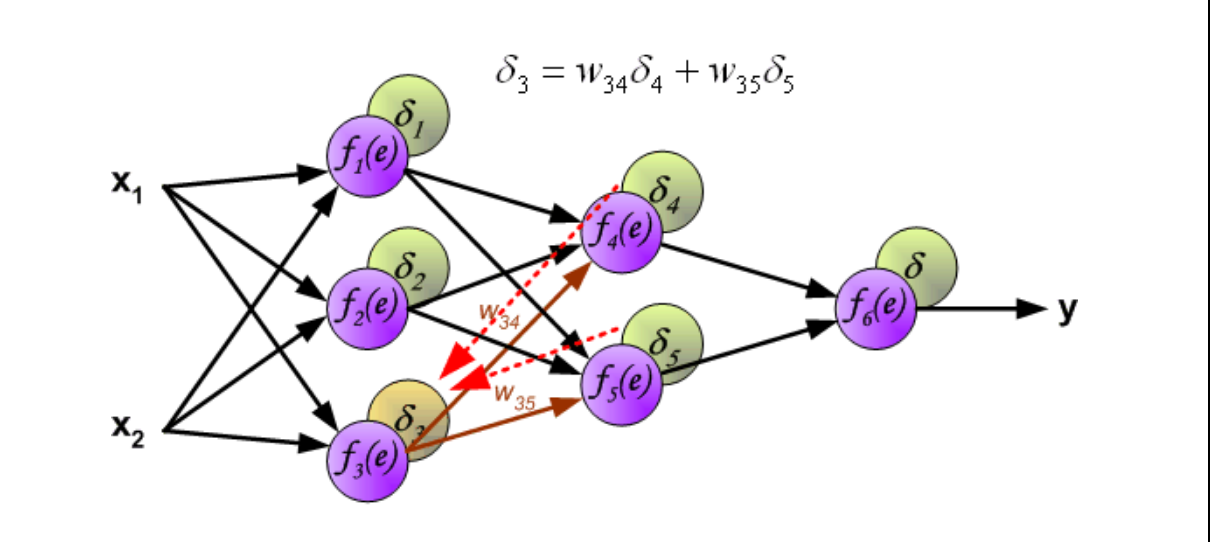 Pergunta: A fórmula do artigo do Brillant que voce citou ela é equivalente ao que está sendo feito nessa outra imagem do HomeEdu que citei acima ? Essa imagem do HomeEdu está ilustrando a mesma coisa que a formula do Brillant mostra?
Pergunta: A fórmula do artigo do Brillant que voce citou ela é equivalente ao que está sendo feito nessa outra imagem do HomeEdu que citei acima ? Essa imagem do HomeEdu está ilustrando a mesma coisa que a formula do Brillant mostra?