Olá William, tudo bem com você?
O método groupby é utilizado para agrupar dados com base em uma ou mais colunas. O que ele faz é dividir o DataFrame em grupos, baseado nos valores únicos da coluna especificada, e então permite a aplicação de funções de agregação a cada grupo separadamente.
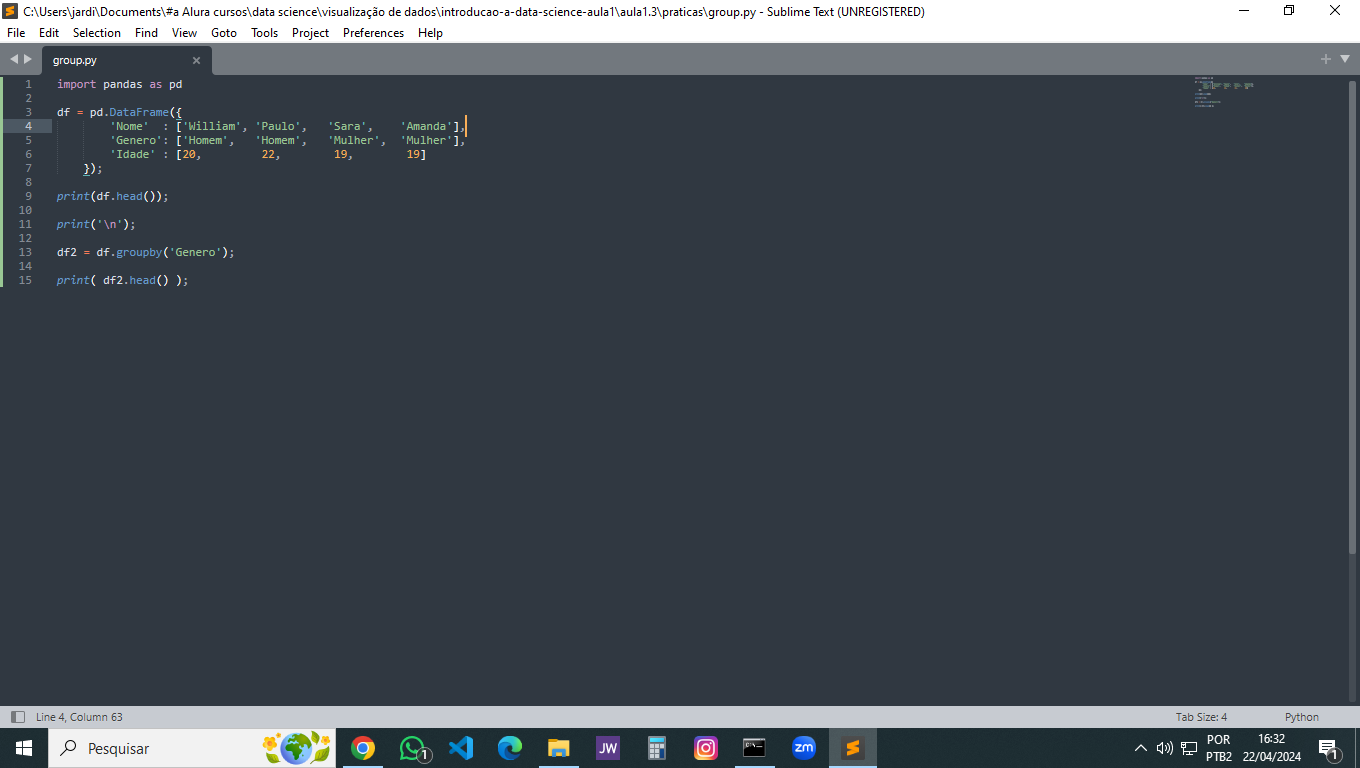
Quando utilizamos, df.groupby('Genero'), indica que o DataFrame será agrupado com base na coluna Genero. No entanto, apenas usar groupby não altera visualmente o DataFrame original porque ele cria um objeto DataFrameGroupBy, que é uma espécie de contêiner intermediário para os grupos, e não um DataFrame pronto para visualização.
Para exibirmos o efeito do groupby, precisamos aplicar uma função de agregação aos grupos. Funções de agregação comuns incluem sum(), mean(), max(), min(), entre outras. Por exemplo, se quisermos a média das idades por gênero, podemos utilizar o seguinte código:
df_agrupado = df.groupby('Genero')['Idade'].mean()
print(df_agrupado)
Isso retornaria um novo DataFrame com a média de idade para cada gênero. Exemplo:
| Genero | Idade |
|---|
| Homem | 21.0 |
| Mulher | 19.0 |
Se você apenas quer ver os grupos sem aplicar uma função de agregação, você pode iterar sobre o objeto DataFrameGroupBy:
for nome, grupo in df.groupby('Genero'):
print(nome)
print(grupo )
Isso imprimirá o nome de cada grupo (os valores únicos da coluna 'Genero') e o DataFrame correspondente a cada grupo, exemplo:

Espero ter ajudado. Conte com o apoio do Fórum na sua jornada. Fico à disposição. Abraços e bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!

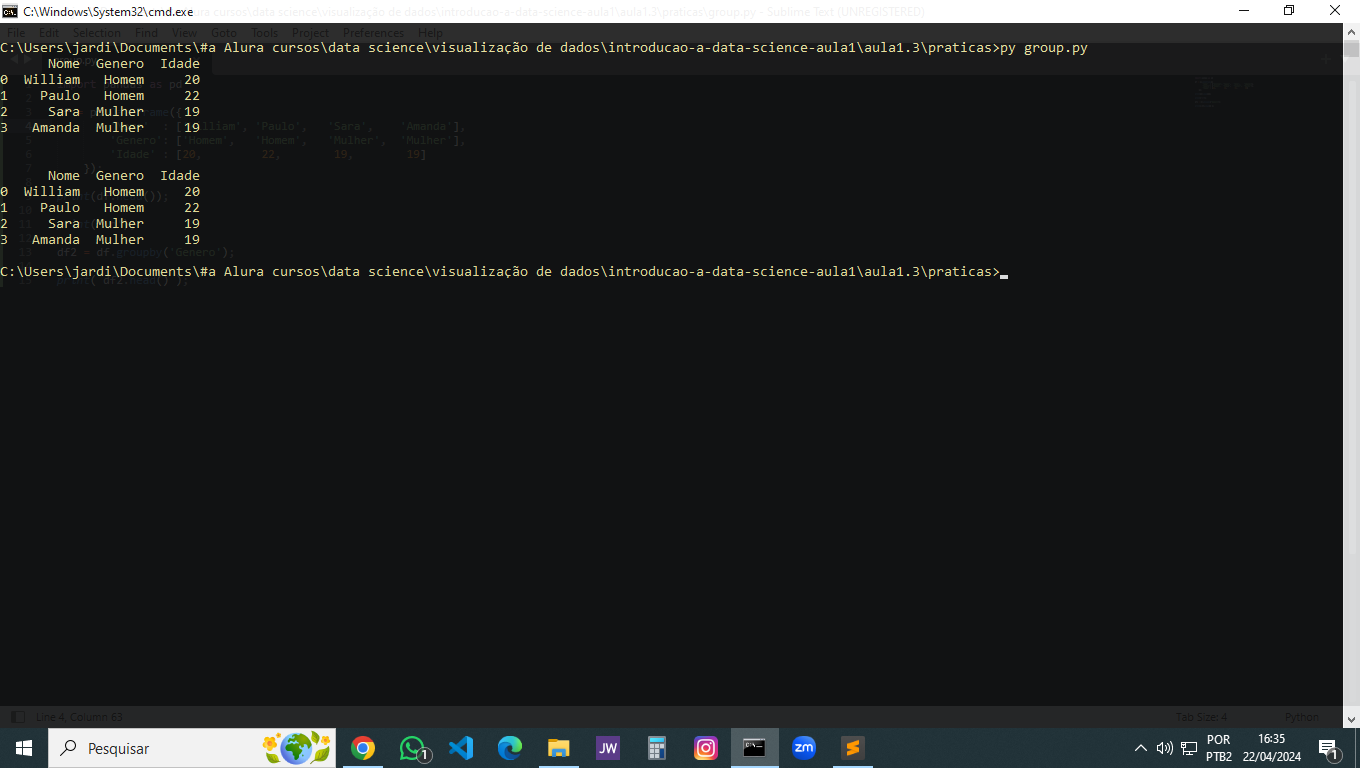
 Comparando visualmente, parece que o resultado antes do group by foi exatamente o mesmo de depois de usar o groupby
Comparando visualmente, parece que o resultado antes do group by foi exatamente o mesmo de depois de usar o groupby
