
Terminei meu boxplot:
sns.boxplot(data = renda_10000,
x = renda_10000.Renda,
y = renda_10000.UF).figure.set_size_inches(15,12)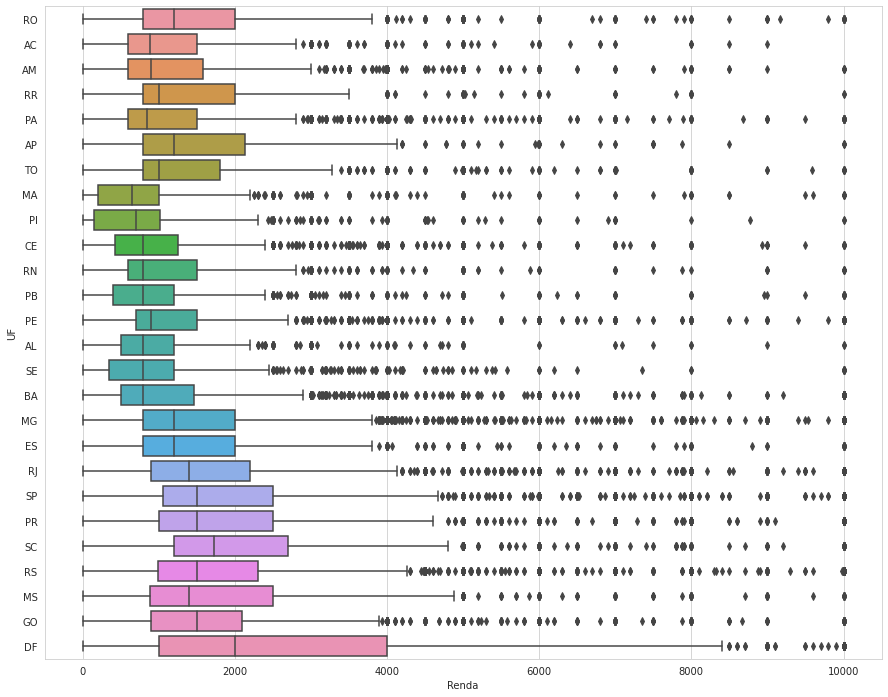
Porém, para melhorar minha análise gráfica, decido separar cada estado pelas cinco regiões do IBGE. Logo, dupliquei a coluna de UF e substitui com .map com o nome de cada região do país:
renda_10000['Região'] = renda_10000['Região'].map({'RO': 'Norte',
'AC': 'Norte', 'AM': 'Norte', 'RR': 'Norte', 'PA': 'Norte',
'AP': 'Norte', 'TO': 'Norte',
'MA': 'Nordeste', 'PI': 'Nordeste', 'CE': 'Nordeste',
'RN': 'Nordeste', 'PB': 'Nordeste', 'PE': 'Nordeste',
'AL': 'Nordeste', 'SE': 'Nordeste', 'BA': 'Nordeste',
'MG': 'Sudeste', 'ES': 'Sudeste', 'RJ': 'Sudeste', 'SP': 'Sudeste',
'PR': 'Sul', 'SC': 'Sul', 'RS': 'Sul',
'MS': 'Centro-oeste', 'MG': 'Centro-oeste', 'GO': 'Centro-oeste',
'DF': 'Centro-oeste'})
renda_10000.head()<ipython-input-204-65f33cfe9f4c>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
renda_10000['Região'] = renda_10000['Região'].map({'RO': 'Norte',| UF | Gênero | Idade | Cor | Anos_de_Estudo | Renda | Altura | Classe | Região | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | RO | Masculino | 23 | Parda | 12 | 800 | 1.603808 | E | Norte |
| 1 | RO | Feminino | 23 | Branca | 12 | 1150 | 1.739790 | E | Norte |
| 2 | RO | Feminino | 35 | Parda | 15 | 880 | 1.760444 | E | Norte |
| 3 | RO | Masculino | 46 | Branca | 6 | 3500 | 1.783158 | D | Norte |
| 4 | RO | Feminino | 47 | Parda | 9 | 150 | 1.690631 | E | Norte |
Então, resultou em :
sns.boxplot(data = renda_10000,
x = renda_10000.Renda,
y = renda_10000.Região).figure.set_size_inches(15,12)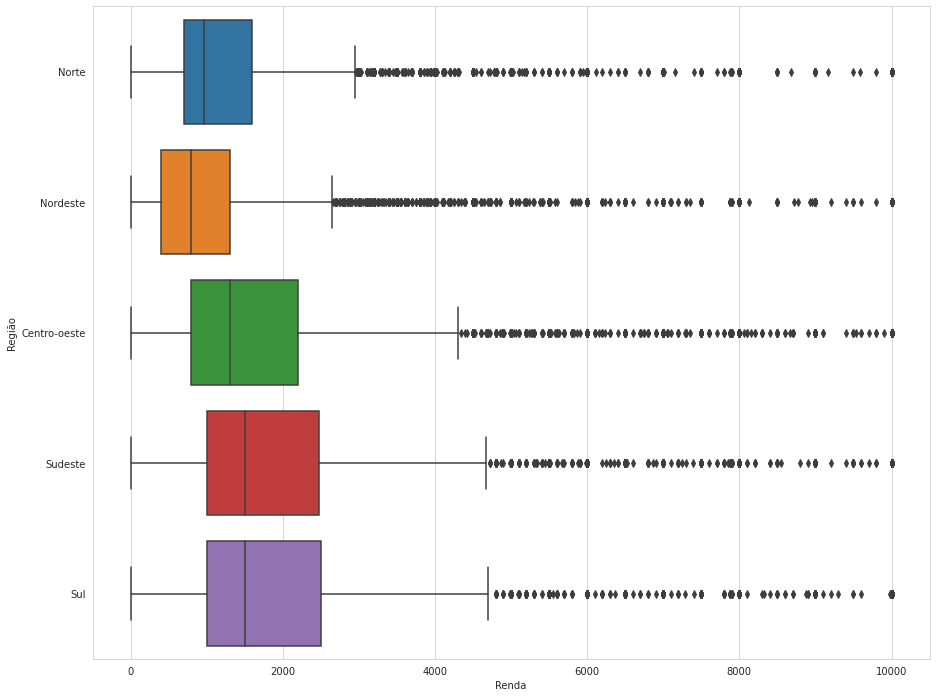
Enfim, eu gostaria de procurar uma meneira melhor de agrupar o estado de cada linha do DataFrame, mas sem precisar duplicar a coluna dos UF, substituir com .map e, principalmente, não repetir a cópia e cola dos nomes da cada região para cada UF (criando as chaves e os valores do dict). Gostaria de uma função que verificasse o valor do UF da linha e atribuísse o valor para a coluna nova de Regiões.
Para contextualizar: renda_10000 = dados.query('Renda <= 10000'). Sendo que dados é o DataFrame original do IBGE. Exclui todos que tinham uma renda maior que R$10.000,00.

