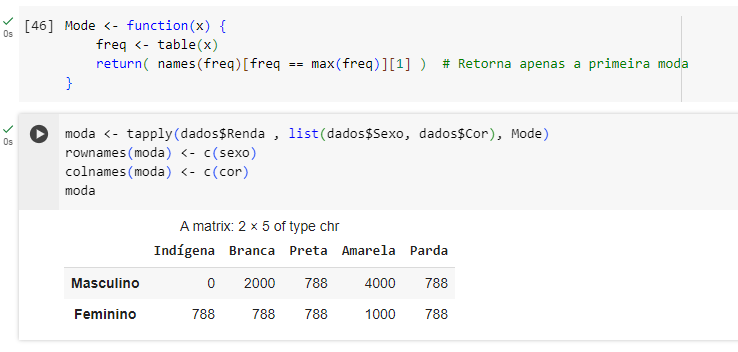
Sendo que os valores de Renda são quantitativos contínuos, a moda faria mais sentido em valores qualitativos ou quantitativos discretos. Contudo, fico curioso como poderia fazer a moda com o tapply(). Tentei fazer, mas ficou errado por causa do excesso de colunas à direita.
Mode <- function(x) {
freq <- table(x)
return( names(freq)[freq == max(freq)] )
}
moda <- tapply(dados$Renda , list(dados$Sexo, dados$Cor), Mode)
rownames(moda) <- c(sexo)
colnames(moda) <- c(cor)
moda
| Indígena | Branca | Preta | Amarela | Parda | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Masculino | 0 | 2000 | 788 | 4000, 5000 | 788 | |||||
| Feminino | 788 | 788 | 788 | 1000, 3000 | 788 |
Precisarei importar a biblioteca library(modeest)? E usar a função mfv()? Funciona o tapply()?
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| Text | Text | Text |