
Na segunda aula, aprendemos a fazer o histograma usando o Seaborn e comparamos com o histograma gerado pelo Pandas.
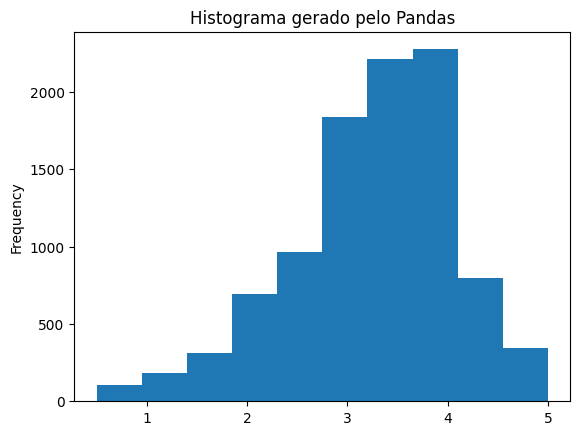
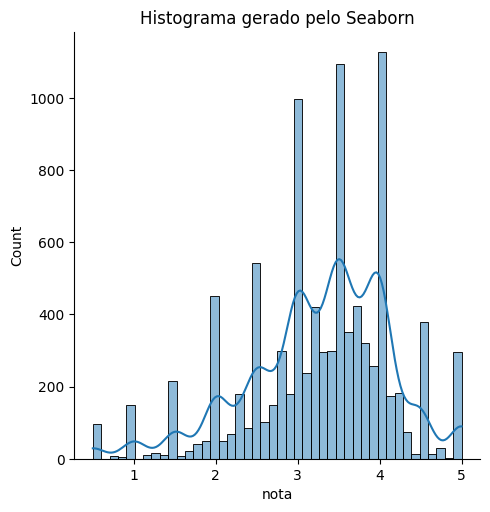
Ao comparar os gráficos, fiquei pensando que o gerado pelo Seaborn pode revelar uma tendência que não apareceu no outro: de haver uma consistência entre as notas de cada filme. Isso porque a média sobe consideravelmente nas notas possíveis de serem atribuídas aos filmes (exatas e terminadas em meio). Imagino que, quando um filme recebe notas muito diferentes, a média tenha mais casas decimais e valores mais quebrados.
Foi assim que verifiquei quais notas foram utilizadas pelos usuários:
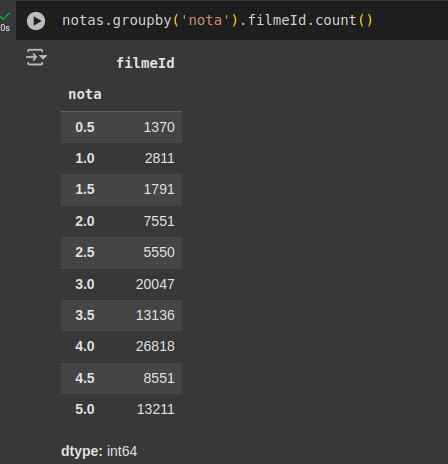
Minhas dúvidas:
- Essa análise está correta, ou pelo menos no caminho certo?
- Como eu posso me aprofundar nessa hipótese?
- Eu usei a melhor forma para verificar as notas selecionáveis?
Valeu!

