
Sabendo que a partir da versão 0.13 por padrão o Dummy Classifier utiliza a estratégia prior, no código a seguir, o resultado da acurácia é fixada em 58%, independente do número de vezes que executo, seja rodando apenas o bloco ou o programa inteiro:
from sklearn.dummy import DummyClassifier
dummy_prior = DummyClassifier() # Utiliza por padrao a estategia `prior`
dummy_prior.fit(x_treino, y_treino)
previsoes = dummy_prior.predict (x_teste)
acuracia = accuracy_score(y_teste, previsoes) * 100
print ("A acuracia do dummy_prior foi de %.2f%%" % acuracia)

O mesmo ocorre para a estratégia definida como most_frequent a acurácia permanece fixada também em 58%, repetindo a situação do classificador que usa a estratégia prior:
dummy_mostfrequent = DummyClassifier(strategy= "most_frequent")
dummy_mostfrequent.fit(x_treino, y_treino)
previsoes = dummy_mostfrequent.predict(x_teste)
acuracia = accuracy_score(y_teste, previsoes) * 100
print("A acurácia do dummy mostfrequent foi %.2f%%" % acuracia)
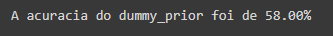
Se o parâmetro da estratégia do Dummy Classifier for configurado como stratified, o valor altera a cada iteração, como previsto pelo instrutor no vídeo:
from sklearn.dummy import DummyClassifier
dummy_stratified = DummyClassifier(strategy="stratified")
dummy_stratified.fit(x_treino, y_treino)
previsoes = dummy_stratified.predict (x_teste)
acuracia = accuracy_score(y_teste, previsoes) * 100
print ("A acuracia do dummy_stratified foi de %.2f%%" % acuracia)
A não ser que passe como argumento o random_state para o Dummy Classifier da seguinte forma, mantendo a acurácia fixa em um valor:
dummy_stratified = DummyClassifier(strategy= "stratified", random_state= SEED)
 Gostaria de entender o que está acontecendo aqui.
Gostaria de entender o que está acontecendo aqui.

