Olá.
Conforme executei o passo a passo da aula, ocorreu uma diferença entre os meus resultados e o do curso, e não consigo descobrir porque.
Em '06 Percentual dos tipos de imóveis', na segunda linha de código os resultados começaram a ter pequenas divergências.
df.Tipo.value_counts()
Resultado:
| **Tipo** | |
| Apartamento | 19532 |
| Casa de condomínio | 996 |
| Casa | 967 |
| Quitinete | 836 |
| Flat | 476 |
| Casa da vila | 249 |
| Loft | 51 |
| Studio | 4 |
Name: **count**, dtype: int64
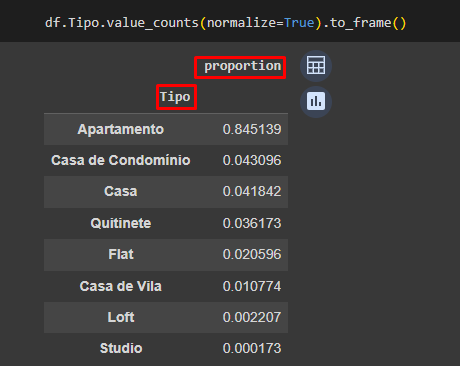
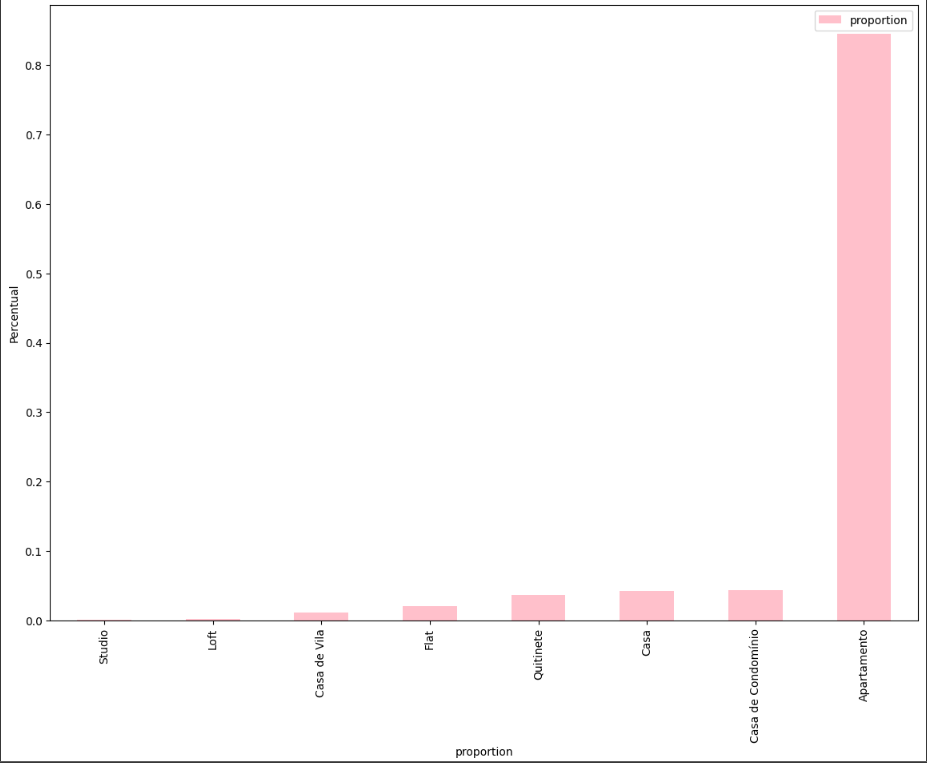
df.Tipo.value_counts(normalize=True)
Resultado:
| **Tipo** | |
| Apartamento | 0.845139 |
| Casa de condomínio | 0.043096 |
| Casa | 0.041842 |
| Quitinete | 0.036173 |
| Flat | 0.020596 |
| Casa da vila | 0.010774 |
| Loft | 0.002207 |
| Studio | 0.000173 |
Name: **proportion**, dtype: float64
E quando executo o código abaixo, o nome 'Tipo' fica centralizado sobre a tabela, e não especificando o nome da coluna com a porcentagem dos imóveis.
df.Tipo.value_counts(normalize=True).to_frame()
Então quando tento executar o código para organizar os valores (abaixo) por ordem numérica, não funciona, já que não reconhece a coluna, e ele reproduz a mesma tabela novamente.
df.Tipo.value_counts(normalize=True).to_frame().sort_values('Tipo')
É uma diferença de versão, ou fiz algo errado em algum lugar e nao estou achando?