Olá João, tudo bem com você?
Peço desculpas pela demora em obter um retorno.
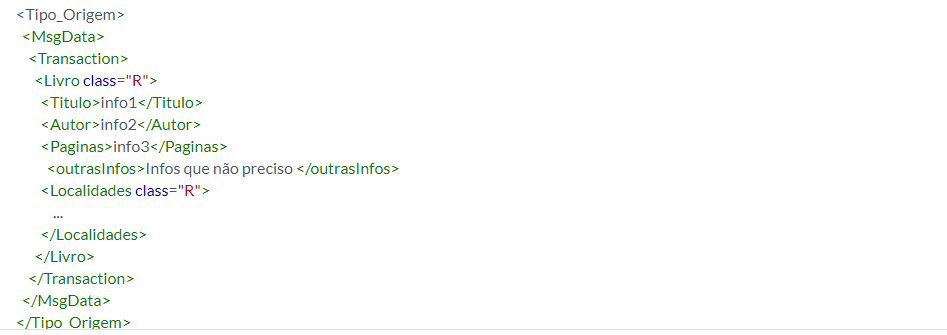
Uma das forms de ignorar as tags <Titulo>, <Autor> e <Paginas> do seu XML ao realizar o parsing é fazer um loop que ignora estas tags, por exemplo:
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class TesteXML {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("arquivo.xml");
Element root = document.getDocumentElement();
NodeList livros = root.getElementsByTagName("Livro");
for (int i = 0; i < livros.getLength(); i++) {
Node livro = livros.item(i);
NodeList elementosDesejados = ((Element) livro).getElementsByTagName("*");
for (int j = 0; j < elementosDesejados.getLength(); j++) {
Node elemento = elementosDesejados.item(j);
String tagName = elemento.getNodeName();
if (!tagName.equals("Titulo") && !tagName.equals("Autor") && !tagName.equals("Paginas")) {
System.out.println(tagName + ": " + elemento.getTextContent());
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Neste exemplo, adicionamos um loop interno para percorrer todos os elementos filhos de <Livro>. Em seguida, verificamos se o nome da tag do elemento é diferente de "Titulo", "Autor" e "Paginas". Se for diferente, podemos considerar que é um elemento desejado e fazer algo com ele (como imprimir seu conteúdo). Dessa forma, os elementos indesejados serão ignorados. Todavia, vale ressaltar que como é um assunto externo ao curso e que não tenho acesso ao cenário completo do projeto, outros testes terão de ser feitos a fim de obter o resultado esperado, mas espero que esta resposta seja um bom ponto de partida para a resolução do seu problema.
Espero ter ajudado. Continue mergulhando em conhecimento e não hesite em voltar ao fórum para continuar aprendendo e interagindo com a comunidade.
Abraços e bons estudos!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!