Olá, Kamilla! Tudo bem? Espero que sim!
Você pode utilizar os métodos do próprio Pandas para fazer essa tabela de frequência relativa. Nós vamos começar utilizando o DataFrame do curso:
import pandas as pd
df = pd.read_csv("dados.csv")
# Código para trocar as variáveis categórias de Cor.
df['Cor']= df['Cor'].replace({0:"Indígena",
2:"Branca",
4:"Preta",
6:"Amarela",
8:"Parda",
9:"Sem declaração"})
df.head(5)
E a saída esperada é:
| UF | Sexo | Idade | Cor | Anos de Estudo | Renda | Altura |
|---|
| 0 | 11 | 0 | 23 | Parda | 12 | 800 | 1.60381 |
| 1 | 11 | 1 | 23 | Branca | 12 | 1150 | 1.73979 |
| 2 | 11 | 1 | 35 | Parda | 15 | 880 | 1.76044 |
| 3 | 11 | 0 | 46 | Branca | 6 | 3500 | 1.78316 |
| 4 | 11 | 1 | 47 | Parda | 9 | 150 | 1.69063 |
Distribuição Populacional
Para calcular a distribuição populacional nós vamos fazer uma contagem das ocorrências para cada valor em Cor, e depois nós vamos utilizar o parâmetro normalize = True para receber a frequência relativa. Da seguinte maneira:
distribuicao_populacional = df['Cor'].value_counts(normalize = True).to_frame() * 100
distribuicao_populacional
Com a saída esperada:
| Cor |
|---|
| Parda | 46.753 |
| Branca | 41.4042 |
| Preta | 10.9201 |
| Indígena | 0.464602 |
| Amarela | 0.458095 |
O método to_frame()foi utilizado para transformar o resultado em um Pandas DataFrame, isso vai facilitar a junção com o próximo resultado.
Distribuição de Renda
Para a distribuição de Renda, nós precisamos primeiro fazer uma operação de agrupamento dos dados através da coluna Cor, e somente depois de ter os dados agrupados por ela, nós podemos calcular a proporção deles com base na renda total.
Para fazer o agrupamento, nós vamos usar o método groupby(), precedido da função de soma. E o resultado disso vai ser normalizado com o valor da soma de todas as rendas. Conforme o código abaixo:
distribuicao_renda = df[['Cor', 'Renda']].groupby('Cor').sum() / sum(df['Renda']) * 100
distribuicao_renda
Que possui saída esperada:
| Cor | Renda |
|---|
| Amarela | 0.957903 |
| Branca | 55.4507 |
| Indígena | 0.342088 |
| Parda | 35.3758 |
| Preta | 7.87349 |
Agora nós temos dois pd.DataFrame com os mesmos índices, podemos utilizar a função pd.concat(), que recebe uma lista de DataFrames e os junta através de linhas ou colunas (parâmetro axis). Então o nosso código fica:
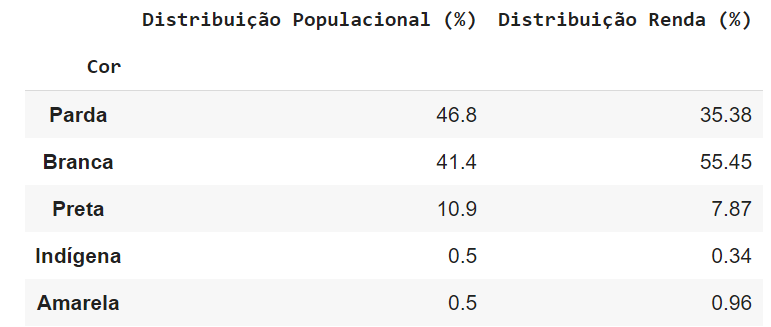
pd.concat([distribuicao_populacional, distribuicao_renda], axis = 1)
E a saída esperada é:
| Cor | Renda |
|---|
| Parda | 46.753 | 35.3758 |
| Branca | 41.4042 | 55.4507 |
| Preta | 10.9201 | 7.87349 |
| Indígena | 0.464602 | 0.342088 |
| Amarela | 0.458095 | 0.957903 |
Pronto, agora nós temos um procedimento que calcula a mesma tabela para vários valores do seu Dataset :D.
Se ainda tiver alguma dúvida, estou por aqui. Ótimos estudos e grande abraço!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!