Professores, por que o INPLACE???
Você está vendo a versão anterior da nova experiência da Alura que estamos preparando para você. Em breve, ela ganha uma identidade visual novinha totalmente pensada em potencializar seus estudos!

Professores, por que o INPLACE???


Oii Eduardo! Como você está?
Utilizamos o inplace = True para que a alteração que estamos realizando, seja salva de forma permanente no nosso dataframe e não apenas na célula onde realizamos a execução desse comando.
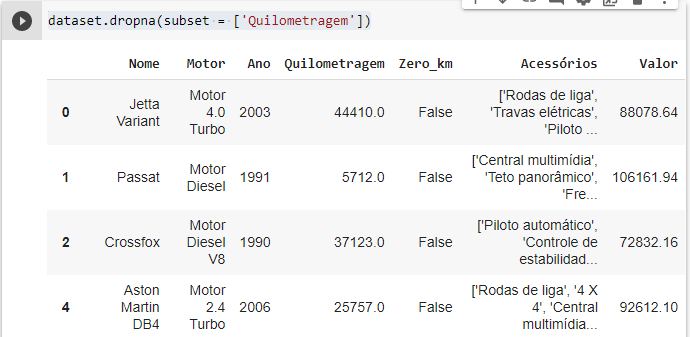
Então, se executarmos dataset.dropna(subset = ['Quilometragem']) em uma célula, teremos como resultado um dataframe onde, as linhas que possuem dados nulos na coluna Quilometragem são deletadas. No entanto, se na célula seguinte visualizarmos nosso dataframe dataset vamos perceber que, ele não está com as alterações que fizemos na célula anterior, e isso porque nós não salvamos aquela alteração diretamente no nosso dataframe, observe:
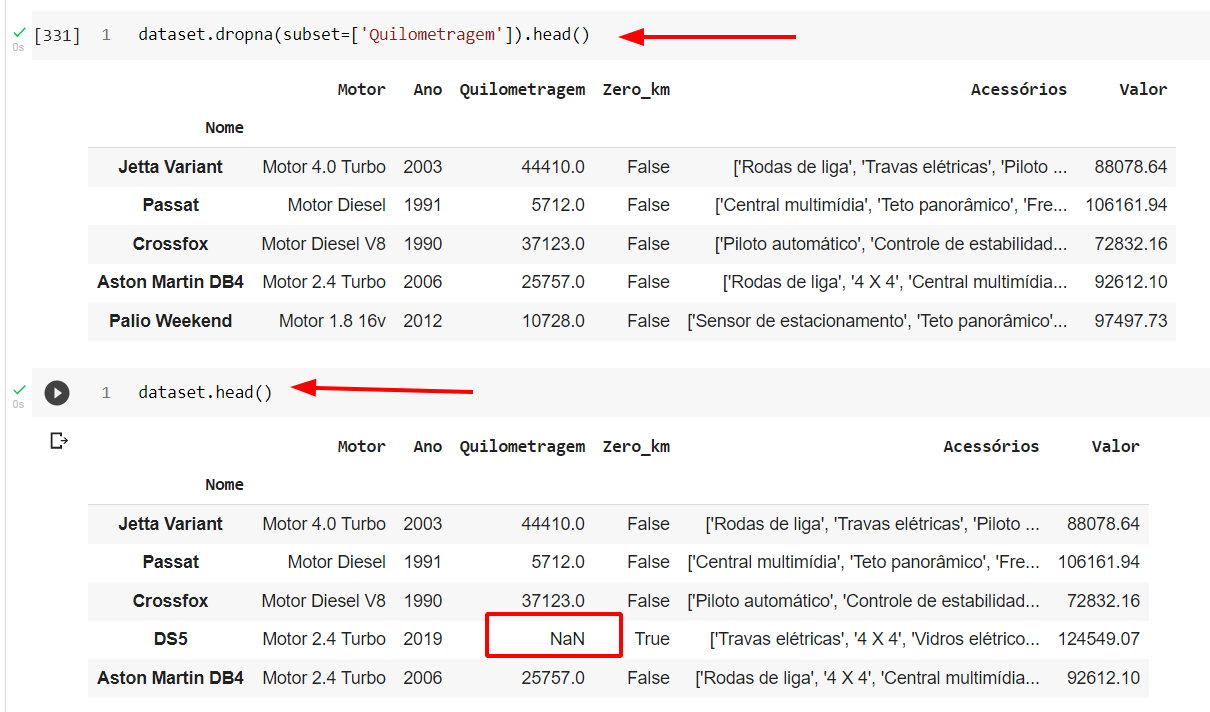
Sendo assim, para salvar essa alteração no dataframe, podemos utilizar o inplace:
dataset.dropna(subset=['Quilometragem'], inplace=True)Ou, podemos atribuir o dataframe com o método para o próprio dataframe:
dataset = dataset.dropna(subset=['Quilometragem'])
dataset.head()Espero ter ajudado. Qualquer dúvida é só chamar :)
Bom dia Professora.
Certo, cheguei na parte aqui do PANDAS que explica um pouco mais sobre o drop.duplicate e fala sobre o INPLACE, agora ficou claro.
Obrigado.