Olá, Jean, tudo bem?
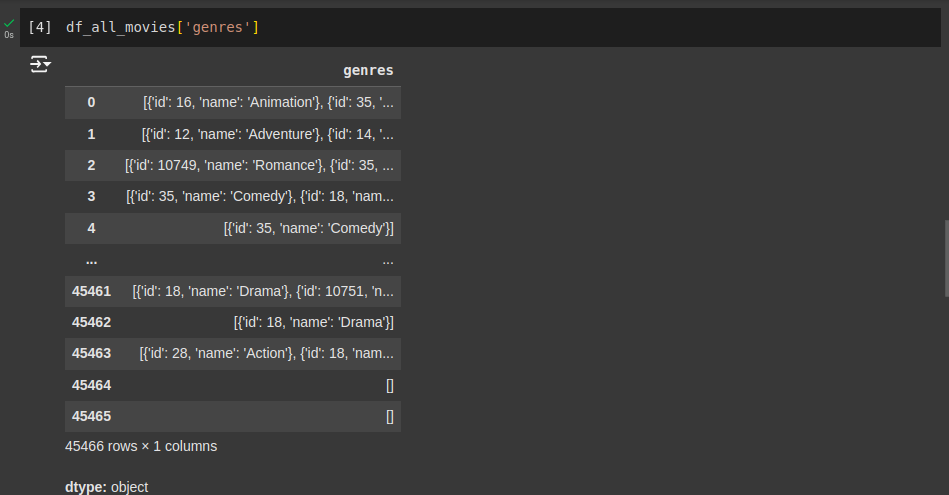
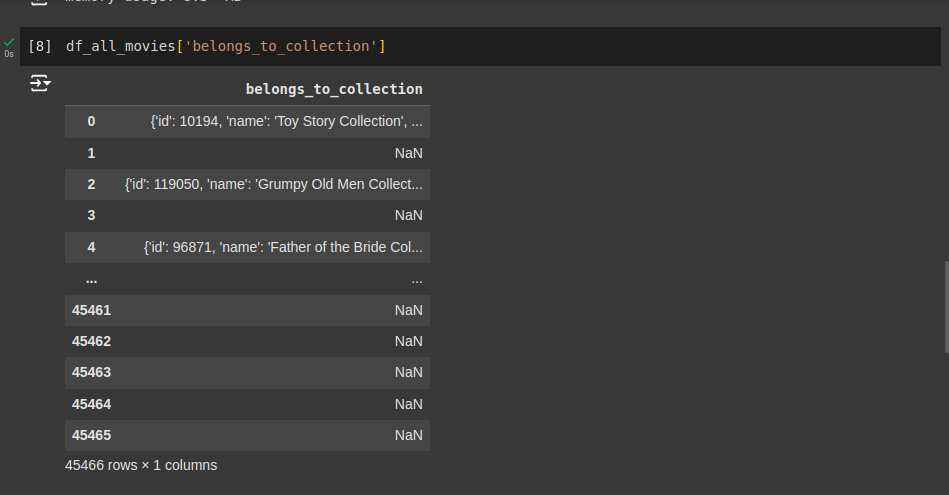
Apesar de genres e belongs_to_collection parecerem conter listas ou dicionários, na verdade elas são strings (texto) no DataFrame. Isso pode ocorrer porque o pandas não converte automaticamente JSON serializado em objetos Python. Por exemplo: "[{'id': 16, 'name': 'Animation'}, {'id': 35, 'name': 'Comedy'}]". O pandas interpreta isso como uma string, e não como uma lista de dicionários.
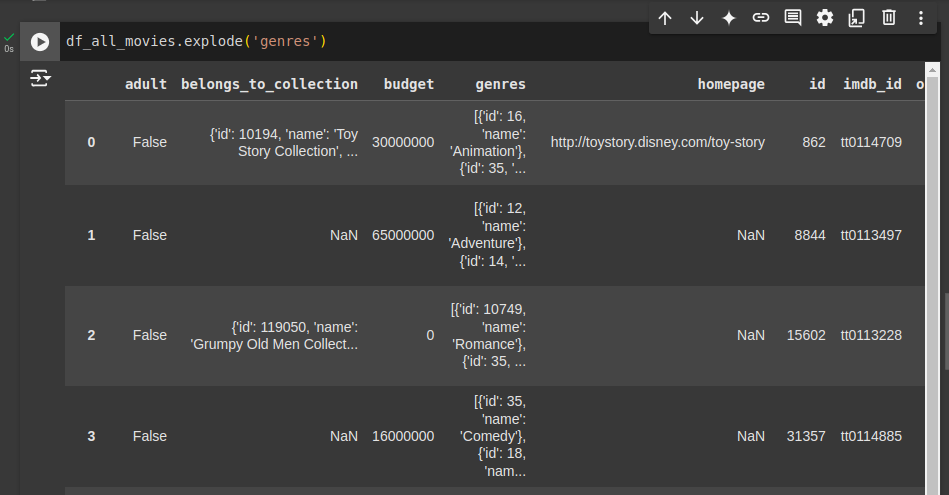
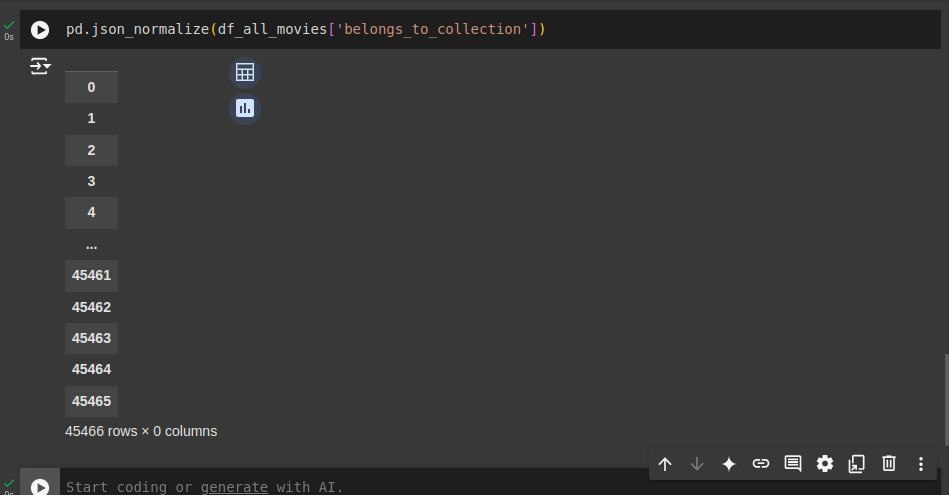
Como genres não é uma lista de objetos Python, mas sim uma string, o método explode não consegue separar os elementos. Outra questão é que a função pd.json_normalize funciona apenas com dados no formato de dicionários. Se a coluna contém valores NaN ou strings não desserializadas, o resultado será vazio.
Para solucionar, primeiro, você terá que transformar as colunas que contêm listas ou dicionários em objetos Python utilizáveis, neste caso, você pode converter usando ast.literal_eval . Depois, aplique o explode ou pd.json_normalize.
Uma sugestão de código é:
import pandas as pd
import ast
# Carregar o dataset
df = pd.read_csv('movies_metadata.csv')
# Desserializar a coluna 'genres' de string para lista de dicionários
df['genres'] = df['genres'].apply(lambda x: ast.literal_eval(x) if isinstance(x, str) else x)
# Explodir a coluna 'genres' (uma linha para cada gênero)
exploded_genres = df.explode('genres')
# Normalizar os dicionários na coluna 'genres'
normalized_genres = pd.json_normalize(exploded_genres['genres'])
# Combinar os gêneros normalizados com o DataFrame original
df_with_genres = pd.concat([exploded_genres.reset_index(drop=True), normalized_genres], axis=1)
# Resultado
df_with_genres.head()
Espero ter ajudado.
Qualquer dúvida, não hesite em compartilhar no fórum.
Abraços!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado