Olá, Otto! Vou muito bem, obrigado!
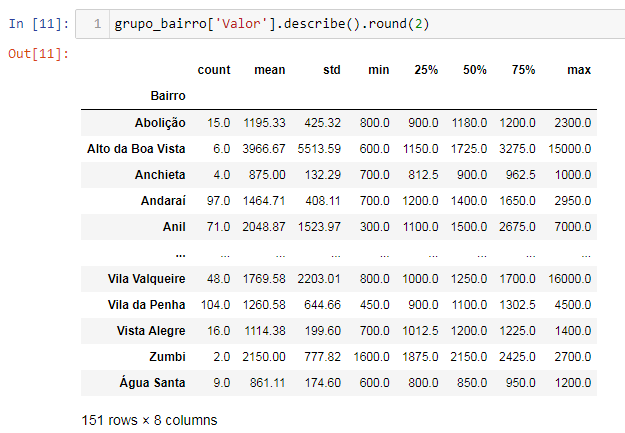
O método pd.DataFrame.describe() te retorna um objeto do tipo pd.DataFrame, então isso significa que essa resposta que é mostrada na tela também pode ser tratada como uma tabela do Pandas, e nós só precisamos armazená-la em uma variável e depois utilizar.
Nós podemos armazená-la fazendo:
df_descricao = grupo_bairro['Valor'].describe().round(2)
df_descricao
E podemos verificar que realmente é um objeto pd.DataFrame do Pandas usando o comando:
type(df_descricao)
Saída:
pandas.core.frame.DataFrame
E agora que nós temos um Dataframe do Pandas, nós podemos tratar, por exemplo, a coluna mean (ou a std) e obter os maiores valores de média ordenando o DataFrame por esta coluna. E para ordenar DataFrames utilizamos o método pd.DataFrame.sort_values(), com o parâmetro asceding = False para ir do maior para o menor, em ordem decrescente. Da seguinte maneira
df_descricao['mean'].sort_values(ascending = False)
E a saída esperada é:
Bairro
Ipanema 9352.00
Botafogo 8791.83
Leblon 8746.34
Barra da Tijuca 7069.55
Copacabana 4126.68
Flamengo 4113.53
Tijuca 2043.52
Name: mean, dtype: float64
Desse modo, você consegue ter uma lista ordenada dos bairros com os maiores valores observados.
Essa ainda é uma opção que mostra tela reduzida para Datasets muito grandes, mas você pode também alterar a opção de limite de visualização das linhas do Pandas e imprimir a tabela inteira, o que não é recomendável. Para isso, utilize o comando:
with pd.option_context('display.max_rows', None, 'display.max_columns', None): # more options can be specified also
print(df)
Se ainda tiver alguma dúvida, estou por aqui. Ótimos estudos e grande abraço!
Caso este post tenha lhe ajudado, por favor, marcar como solucionado ✓. Bons Estudos!